QumuloдҪ“зі»з»“жһ„зҷҪзҡ®д№Ұ
еҺҹеҲӣпјҡ иҜ‘иҖ… еј е…ӢиҜҡ пјҢдёҖеҲҮиҚЈиҖҖеҪ’дәҺе…ӢиҜҡпјҢе“ҲйҮҢи·Ҝдәҡ
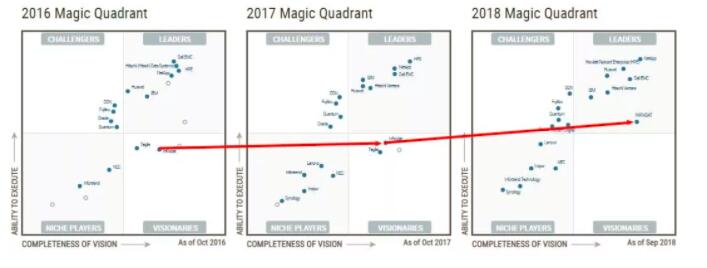
QumuloеңЁ2017е№ҙе…ҘеӣҙGartnerйӯ”еҠӣиұЎйҷҗпјҢд»…дёӨе№ҙе°ұжҲҗдёәдәҶиҜҘйўҶеҹҹзҡ„йўҶеҜјиҖ…гҖӮ
Qumuloзҡ„еҲӣе§ӢдәәдёҖе…ұ3дәәпјҢ他们йғҪжҳҜIsilonзҡ„еӨ§зүӣгҖӮIsilonдёҖе…ұжңү62йЎ№дё“еҲ©пјҢ他们дёүдәәе°ұжӢҘжңү55йЎ№гҖӮ
---иҜ‘ж–ҮејҖе§Ӣ---
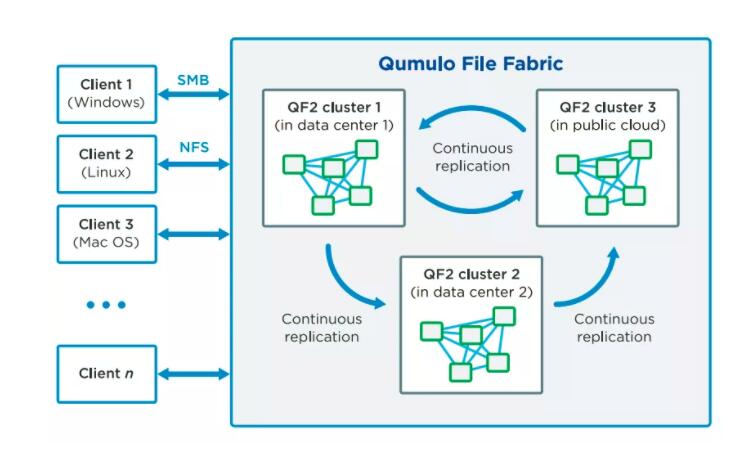
Qumulo FileFabric (QF2) ж”ҜжҢҒжң¬ең°йғЁзҪІе’Ңи·Ёдә‘йғЁзҪІпјҢзҷҫдәҝзә§ж–Ү件ж”ҜжҢҒпјҢжһҒй«ҳжү©е……иғҪеҠӣзҡ„ж–Ү件еӯҳеӮЁгҖӮ
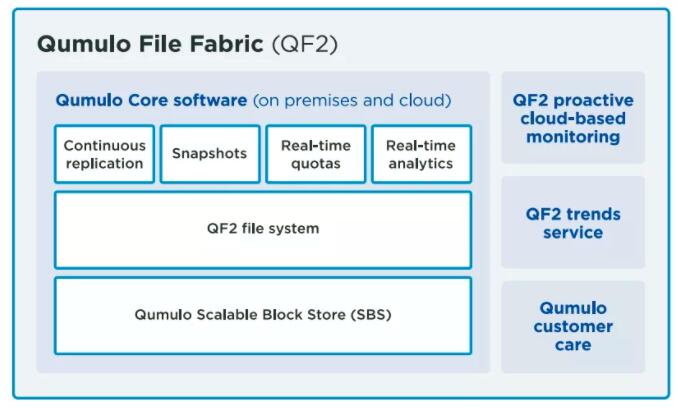
QF2з”ұиҪҜ件е’ҢжңҚеҠЎдёӨйғЁеҲҶз»„жҲҗпјҢеҸҜж №жҚ®йў„з®—зҒөжҙ»еҸ–иҲҚгҖӮ
ж ёеҝғжҳҜиҝҗиЎҢеңЁQF2йӣҶзҫӨдёӯзҡ„иҠӮзӮ№дёҠзҡ„иҪҜ件пјҢеҢ…жӢ¬ејәеӨ§зҡ„е®һж—¶еҲҶжһҗгҖҒе®№йҮҸйҷҗйўқгҖҒиҝһз»ӯеӨҚеҲ¶е’Ңеҝ«з…§гҖӮиҖҢе…¶д»–зҡ„еӯҳеӮЁзі»з»ҹд»…д»…еҢ…еҗ«йӣҶжҲҗзҡ„е®һж—¶ж–Ү件е…ғж•°жҚ®иҒҡеҗҲгҖӮ
QF2ж–Ү件系з»ҹжһ„е»әеңЁQumulo Scalable Block Store (SBS)д№ӢдёҠпјҢSBSйҮҮз”Ёжө·йҮҸжү©е……еҲҶеёғејҸж•°жҚ®еә“еҺҹзҗҶ并且йқўеҗ‘ж–Ү件数жҚ®дјҳеҢ–гҖӮSBSжҳҜQF2зҡ„ж•°жҚ®еқ—еұӮпјҢжҸҗдҫӣз®ҖеҚ•йғЁзҪІе’ҢжһҒеәҰеҸҜйқ зҡ„еә•йғЁж”Ҝж’‘гҖӮеӣ жӯӨSBSд№ҹз»ҷдәҶж–Ү件系з»ҹжө·йҮҸжү©е……иғҪеҠӣгҖҒдјҳеҢ–зҡ„жҖ§иғҪеҸҠж•°жҚ®дҝқжҠӨгҖӮ
еҸҰеӨ–пјҢQF2иҝҳжҸҗдҫӣеҹәдәҺдә‘зҡ„зӣ‘жҺ§гҖҒи¶ӢеҠҝеҲҶжһҗдҪңдёәеҸҜйҖүжЁЎеқ—пјҢдёҺд№ӢдјҙйҡҸзҡ„иҝҳжңүз»јеҗҲз”ЁжҲ·ж”Ҝж’‘жЁЎеқ—гҖӮдә‘зӣ‘жҺ§еҢ…жӢ¬зұ»дјјзЈҒзӣҳж•…йҡңиҝҷж ·дәӢж•…зҡ„еүҚзһ»жҺўжөӢд»ҘдҫҝдәӢ件зңҹжӯЈеҸ‘з”ҹеүҚи§ЈеҶіж•…йҡңгҖӮеҜ№иҝҮеҺ»дҪҝз”ЁиҝҮзЁӢи¶ӢеҠҝеҲҶжһҗзҡ„и®ҝй—®еҸҜд»Ҙеё®еҠ©з”ЁжҲ·иҠӮзңҒжҲҗжң¬дјҳеҢ–еӯҳеӮЁдҪҝз”ЁжөҒзЁӢгҖӮ
ж ёеҝғиҪҜ件еҸҜд»ҘиҝҗиЎҢеңЁе…¬жңүдә‘дёҠпјҢд№ҹеҸҜд»ҘиҝҗиЎҢеңЁж•°жҚ®дёӯеҝғдёӯе·Ҙдёҡж ҮеҮҶ硬件平еҸ°дёҠпјҢQumuloеҪ“еүҚиҝҗиЎҢеңЁиҮӘе·ұзҡ„QCзі»еҲ—зҷҪзүҢжңәжңҚеҠЎеҷЁдёҠпјҢд№ҹиҝҗиЎҢеңЁHPEйҳҝжіўзҪ—жңҚеҠЎеҷЁдёҠгҖӮ
дәӢе®һдёҠпјҢQF2дёҺзЎ¬д»¶ж— е…іпјҢеҸҜд»Ҙжңҹеҫ…жӣҙеӨҡзҡ„OEMж”Ҝж’‘гҖӮ
QF2зәҜиҪҜ件方ејҸж„Ҹе‘ізқҖеҜ№жҳӮиҙөгҖҒз§Ғжңү硬件еҰӮNVRAMгҖҒInfiniBandдәӨжҚўжңәгҖҒз§Ғжңүй—ӘеӯҳзӯүжІЎжңүдҫқиө–пјҢеҸ–иҖҢд»Јд№Ӣзҡ„жҳҜQF2дҫқйқ HDDе’ҢSSDзҡ„ж ҮеҮҶfirmwareпјҢQF2дёӯзҡ„SSDе’ҢHDDзҡ„з»„еҗҲдҪҝз”Ёе®һзҺ°дәҶеҶ·зғӯж•°жҚ®иҮӘеҠЁеҲҶеұӮпјҢеӣ жӯӨпјҢQF2е®һзҺ°дәҶеңЁдәҢзә§еӯҳеӮЁзҡ„д»·ж јдёҠжҸҗдҫӣй—Әеӯҳзҡ„жҖ§иғҪгҖӮ
QF2д№ҹеҸҜд»ҘеңЁе…¬жңүдә‘дёҠеҲӣе»әпјҲеҪ“еүҚжҳҜAWSпјүпјҢеҹәдәҺдә‘зҡ„QF2йӣҶзҫӨдёӯзҡ„иҠӮзӮ№иҝҗиЎҢжң¬ең°йғЁзҪІзӣёеҗҢзҡ„иҪҜ件пјҢдёҚеҗҢдәҺе…¶д»–йқўеҗ‘дә‘зҡ„ж–Ү件еӯҳеӮЁзі»з»ҹпјҢQF2иҝҗиЎҢеңЁе…¬жңүдә‘дёҠд№ҹжІЎжңүжҖ§иғҪе’Ңе®№йҮҸзҡ„зЎ¬йҷҗеҲ¶гҖӮдёӨиҖ…йғҪеҸҜд»ҘеҖҹеҠ©еўһеҠ иҠӮзӮ№пјҲи®Ўз®—е®һдҫӢе’Ңеқ—еӯҳеӮЁпјүжқҘе®һзҺ°еўһеҠ гҖӮ
еңЁе…¬жңүдә‘дёҠиҝҗиЎҢж—¶пјҢQF2дҪҝз”Ёдә‘зҡ„еқ—еӯҳеӮЁзҡ„ж–№ејҸдёҺSSD/HDDзӣёз»“еҗҲзҡ„жң¬ең°йғЁзҪІж–№ејҸзұ»дјјпјҢQF2з”ЁдҪҺ延иҝҹеқ—еӯҳеӮЁеҒҡй«ҳ延иҝҹеқ—еӯҳеӮЁзҡ„CacheгҖӮ
еңЁжҜҸдёҖдёӘQF2йӣҶзҫӨзҡ„иҠӮзӮ№дёҠпјҢж ёеҝғиҪҜ件еңЁLinuxзҡ„з”ЁжҲ·жҖҒиҝҗиЎҢпјҢеҶ…ж ёжЁЎејҸжҳҜд»…д»…з”ЁдәҺдёҺзү№е®ҡ硬件зӣёе…ізҡ„и®ҫеӨҮй©ұеҠЁзЁӢеәҸгҖӮ
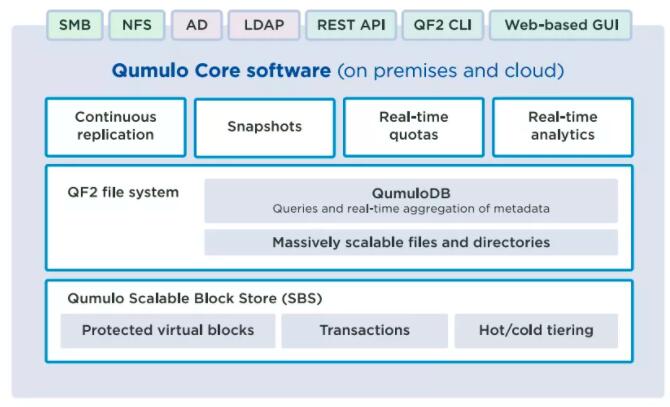
з”ЁжҲ·жҖҒиҝҗиЎҢд№ҹж„Ҹе‘ізқҖеҸҜд»ҘйғЁзҪІиҮӘе·ұзҡ„йҮҚиҰҒеҚҸи®®пјҢеҰӮпјҡSMBгҖҒNFSгҖҒLDAPе’ҢADгҖӮжүҖд»ҘNFSжҳҜд»Ҙзі»з»ҹжңҚеҠЎзҡ„ж–№ејҸиҝҗиЎҢ并且жңүиҮӘе·ұзҡ„з”ЁжҲ·гҖҒз»„зҡ„жҰӮеҝөпјҢеҲҶзҰ»дәҺеҖҹд»ҘиҝҗиЎҢзҡ„еә•йғЁзҡ„ж“ҚдҪңзі»з»ҹгҖӮ
з”ЁжҲ·жҖҒиҝҗиЎҢд№ҹж”№е–„дәҶеҸҜйқ жҖ§гҖӮдҪңдёәзӢ¬з«Ӣзҡ„з”ЁжҲ·жҖҒиҝӣзЁӢпјҢQF2дёҺе…¶д»–зі»з»ҹйғЁд»¶йҡ”зҰ»пјҢйҒҝе…ҚдәҶе…¶д»–йғЁд»¶еј•иө·зҡ„еҶ…еӯҳж•…йҡңеёҰжқҘзҡ„еҪұе“ҚпјҢ并且QF2ејҖеҸ‘зҡ„иҝҮзЁӢйҮҮз”ЁдәҶй«ҳзә§еҶ…еӯҳж ЎйӘҢе·Ҙе…·пјҢе®һзҺ°дәҶеҶ…еӯҳзӣёе…ізҡ„д»Јз Ғж•…йҡңеңЁиҪҜ件жӯЈејҸеҸ‘ж”ҫеүҚзҡ„еүҚжңҹжҺўжөӢгҖӮеҖҹеҠ©дәҺиҪҜ件еҚҮзә§еҸҢеҲҶеүІзӯ–з•ҘпјҢQumuloеҸҜд»ҘиҮӘеҠЁзҡ„еҚҮзә§ж“ҚдҪңзі»з»ҹе’Ңж ёеҝғиҪҜ件д»ҘдҝқиҜҒеҝ«йҖҹе’Ңе®үе…ЁеҸҜйқ гҖӮдҪ еҸҜд»Ҙз®ҖеҚ•зҡ„йҮҚж–°еҗҜеҠЁQF2иҖҢдёҚеҝ…йҮҚеҗҜOSгҖҒиҠӮзӮ№жҲ–йӣҶзҫӨгҖӮ
жө·йҮҸеҸҜжү©е……зҡ„ж–Ү件е’Ңзӣ®еҪ•
еҪ“жңүжө·йҮҸж–Ү件时пјҢзӣ®еҪ•з»“жһ„е’Ңж–Ү件еұһжҖ§жң¬иә«еҸҳжҲҗдәҶеӨ§ж•°жҚ®пјҢзӣҙжҺҘз»“жһңжҳҜеғҸtreewalksиҝҷж ·зҡ„йЎәеәҸеӨ„зҗҶпјҲдј з»ҹеӯҳеӮЁзҡ„еҹәзЎҖпјүеҸҳеҫ—и®Ўз®—дёҠдёҚеңЁеҸҜиЎҢгҖӮзӣёеҸҚпјҢжҹҘиҜўдёҖдёӘеӨ§зҡ„ж–Ү件系з»ҹ并且管зҗҶе®ғе°ұйңҖиҰҒ并иЎҢе’ҢеҲҶеёғејҸз®—жі•зҡ„ж–°зҡ„ж–№жі•гҖӮ
QF2е…·еӨҮиҝҷдёӘзӢ¬зү№зҡ„иғҪеҠӣгҖӮи®ҫи®ЎйғЁзҪІзҡ„еҺҹзҗҶзұ»дјјдәҺзҺ°д»ЈгҖҒеӨ§и§„жЁЎгҖҒеҲҶеёғејҸж•°жҚ®еә“гҖӮеёҰжқҘзҡ„зӣҙжҺҘж•ҲжһңжҳҜж–Ү件系з»ҹе…·жңүж— еҸҜеҢ№ж•Ңзҡ„жү©е……зү№жҖ§гҖӮзӣёжҜ”з…§зҡ„жҳҜдј з»ҹеӯҳеӮЁжІЎжңүе…·еӨҮиҝҷдёӘжү©е……иғҪеҠӣгҖӮ
ж–Ү件系з»ҹдҪҚдәҺиҷҡжӢҹеҢ–зҡ„еқ—еұӮSBSд№ӢдёҠгҖӮеңЁQF2дёӯпјҢиҖ—ж—¶зҡ„дҝқжҠӨгҖҒйҮҚжһ„гҖҒд»ҘеҸҠеҲӨе®ҡSBSеұӮдёӯе“ӘдёӘж•°жҚ®еңЁе“ӘдёӘзЈҒзӣҳдёҠзҡ„е·ҘдҪңдҪҚдәҺж–Ү件系з»ҹд№ӢдёӢгҖӮ
SBSдёӯиҷҡжӢҹеҢ–зҡ„иў«дҝқжҠӨзҡ„еқ—зҡ„еҠҹиғҪжҳҜжң¬ж–Ү件系з»ҹзҡ„дёҖдёӘйҮҚеӨ§дјҳеҠҝгҖӮдј з»ҹеӯҳеӮЁзі»з»ҹжІЎжңүSBSпјҢдҝқжҠӨе®һзҺ°еңЁж–Ү件еұӮйқўдёҠпјҢжҲ–иҖ…ж··еҗҲзҡ„RAIDз»„дёҠпјҢйӮЈж ·дјҡеёҰжқҘдёҘйҮҚзҡ„й—®йўҳпјҢжҜ”еҰӮпјҢеҫҲй•ҝзҡ„йҮҚжһ„ж—¶й—ҙгҖҒе°Ҹж–Ү件зҡ„дҪҺж•ҲеӯҳеӮЁгҖҒд»ҘеҸҠиҫғеӨ§зҡ„зЈҒзӣҳеёғеұҖз®ЎзҗҶејҖй”ҖгҖӮжІЎжңүиҷҡжӢҹеҢ–зҡ„еқ—еұӮпјҢдј з»ҹеӯҳеӮЁзі»з»ҹд№ҹеҝ…йЎ»еңЁе…ғж•°жҚ®еұӮе®һж–Ҫж•°жҚ®дҝқжҠӨпјҢиҝҷдёӘйҷ„еҠ зҡ„еӨҚжқӮеәҰйҷҗеҲ¶дәҶиҝҷдәӣзі»з»ҹдјҳеҢ–еҲҶеёғејҸеӨ„зҗҶиҝҷдәӣзӣ®еҪ•ж•°жҚ®з»“жһ„е’Ңе…ғж•°жҚ®зҡ„иғҪеҠӣгҖӮ
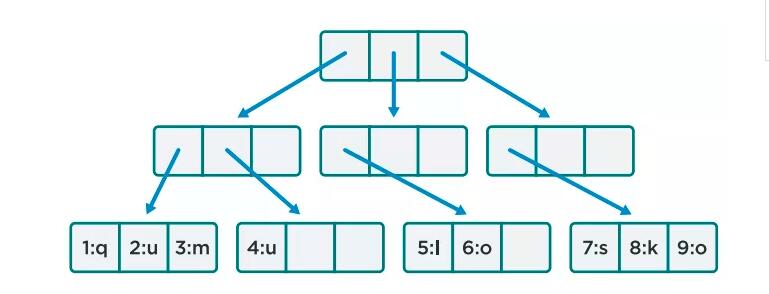
еҜ№дәҺж–Ү件е’Ңзӣ®еҪ•зҡ„жү©е……иғҪеҠӣпјҢQF2ж–Ү件系з»ҹејәеҢ–дҪҝз”ЁдәҶиў«з§°дёәB-treesзҡ„зҙўеј•ж•°жҚ®жһ¶жһ„гҖӮB-treesзү№еҲ«йҖӮз”ЁдәҺиҜ»еҶҷжө·йҮҸж•°жҚ®еқ—зҡ„зі»з»ҹпјҢеӣ дёә他们еұһдәҺвҖңжө…вҖқж•°жҚ®з»“жһ„пјҢеңЁж•°жҚ®йҮҸеўһеҠ ж—¶жңҖе°ҸеҢ–дәҶжҜҸдёӘж“ҚдҪңзҡ„IOиҜ·жұӮзҡ„ж•°йҮҸгҖӮд»ҘB-treesдёәеҹәзЎҖпјҢеҪ“ж•°жҚ®йҮҸеўһеҠ ж—¶иҜ»жҲ–иҖ…жҸ’е…Ҙж•°жҚ®еқ—зҡ„иҝҗз®—ејҖй”Җеўһй•ҝйқһеёёзј“ж…ўгҖӮжүҖд»ҘпјҢB-treesеҜ№ж–Ү件系з»ҹе’ҢеӨ§еһӢж•°жҚ®еә“зҙўеј•жқҘиҜҙйқһеёёе®ҢзҫҺгҖӮ
еңЁQF2дёӯпјҢB-treesжҳҜеҹәдәҺеқ—зҡ„пјҢжҜҸдёӘеқ—4096еӯ—иҠӮгҖӮд»ҘдёӢжҳҜB-treeзҡ„з»“жһ„гҖӮ
жҜҸдёӘ4Kеқ—еҸҜиғҪеҗ«жңүжҢҮй’ҲжҢҮеҗ‘е…¶д»–зҡ„4Kеқ—гҖӮиҜҘдҫӢзҡ„еҲҶеҸүеӣ еӯҗдёә3пјҢеҲҶеҸүеӣ еӯҗжҢҮзҡ„жҳҜж ‘дёӯжҜҸдёӘиҠӮзӮ№еӯ©еӯҗзҡ„ж•°йҮҸпјҲеӯҗиҠӮзӮ№пјүгҖӮ
еҚідҪҝжңүзҷҫдёҮзә§еҲ«зҡ„ж•°жҚ®еқ—пјҢSBSдёӯзҡ„B-treeзҡ„й«ҳеәҰпјҢд»Һж №еҲ°ж•°жҚ®е®һйҷ…зҡ„дҪҚзҪ®пјҢд№ҹе°ұдёӨеҲ°дёүеұӮгҖӮжҜ”еҰӮпјҢдёҠеӣҫдёӯжҹҘжүҫеёҰжңүзҙўеј•еҖј1зҡ„qж ҮзӯҫпјҢд»…йңҖз©ҝиҝҮж ‘зҡ„дёӨеұӮгҖӮ
жң¬ж–Ү件系з»ҹжҠҠB-treeз”ЁдәҺеӨҡдёӘзӣ®зҡ„гҖӮ
жңүдёҖдёӘinode B-treeпјҢжү®жј”жүҖжңүж–Ү件зҙўеј•зҡ„и§’иүІгҖӮInodeеҲ—иЎЁжҳҜдёҖдёӘж ҮеҮҶж–Ү件系з»ҹйғЁзҪІжҠҖжңҜз”ЁдәҺзӣ®еҪ•еұӮзә§ж— е…ізҡ„ж–Ү件系з»ҹдёҖиҮҙжҖ§жЈҖжҹҘгҖӮInodeд№ҹз”ЁдәҺзӣ®еҪ•й«ҳж•Ҳ移еҠЁж“ҚдҪңзҡ„жӣҙж–°зӯүгҖӮ
ж–Ү件е’Ңзӣ®еҪ•еңЁB-treeдёӯиЎЁзҺ°дёәеҗ„иҮӘзҡ„й”®/еҖјеҜ№пјҢжҜ”еҰӮж–Ү件еҗҚгҖҒж–Ү件е°әеҜёгҖҒи®ҝй—®еҲ—иЎЁпјҲACLпјүжҲ–иҖ…POSIXи®ёеҸҜзӯүгҖӮ
й…ҚзҪ®ж•°жҚ®д№ҹжҳҜдёҖдёӘB-treeпјҢеҢ…еҗ«зұ»дјјIPең°еқҖе’ҢйӣҶзҫӨзӯүдҝЎжҒҜгҖӮ
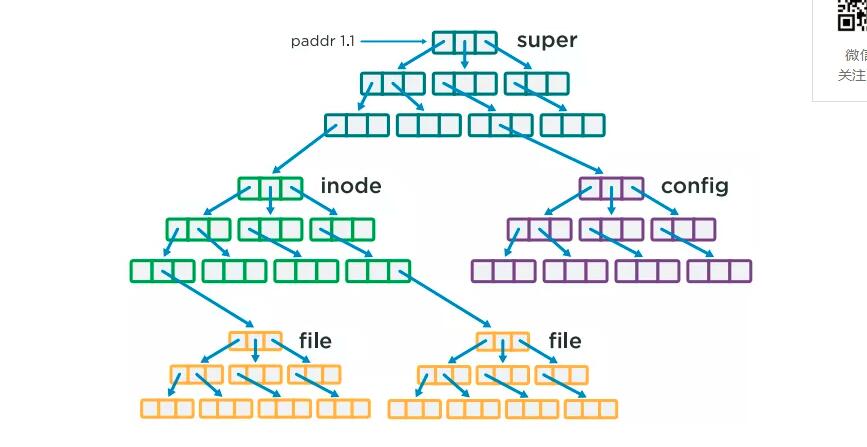
дәӢе®һдёҠпјҢQF2ж–Ү件系з»ҹеҸҜд»ҘзҗҶи§ЈдёәжҳҜдёҖдёӘж ‘зҡ„ж ‘гҖӮеҰӮпјҡ
жңҖйЎ¶еұӮзҡ„ж ‘еҸ«и¶…зә§B-treeгҖӮзі»з»ҹеҗҜеҠЁж—¶пјҢеӨ„зҗҶд»ҺиҝҷйҮҢејҖе§ӢгҖӮж №жҖ»жҳҜеӯҳеӮЁеңЁиҷҡжӢҹдҝқжҠӨзҡ„еқ—зҡ„йҳөеҲ—зҡ„йҰ–дёӘең°еқҖпјҲpaddr 1.1пјүгҖӮж №ж ‘жҢҮеҗ‘е…¶д»–зҡ„B-treesгҖӮдҫӢеҰӮпјҢеҰӮжһңQF2ж–Ү件系з»ҹйңҖиҰҒи®ҝй—®й…ҚзҪ®ж•°жҚ®пјҢе°ұдјҡиө°еҲ°й…ҚзҪ®B-treesгҖӮжҹҘжүҫдёҖдёӘзү№е®ҡзҡ„ж–Ү件пјҢзі»з»ҹиҜўй—®inode B-treeдҪҝз”Ёinodeзј–з ҒдҪңдёәзҙўеј•гҖӮзі»з»ҹз©ҝи¶ҠinodetreeзӣҙеҲ°еҸ‘зҺ°жҢҮеҗ‘ж–Ү件B-treeзҡ„жҢҮй’ҲгҖӮд»ҺйӮЈйҮҢж–Ү件系з»ҹе°ұиғҪеӨҹжүҫеҲ°еҢ…еҗ«ж–Ү件жң¬иә«зҡ„жүҖжңүеҶ…е®№гҖӮзӣ®еҪ•зҡ„еӨ„зҗҶиҝҮзЁӢе’Ңж–Ү件дёҖж ·гҖӮ
дҫқйқ B-treeпјҢжҢҮеҗ‘SBSдёӯиҷҡжӢҹеҢ–зҡ„гҖҒеҸ—дҝқжҠӨзҡ„еқ—еӯҳеӮЁжҳҜж–Ү件系з»ҹеӨ„зҗҶдёҮдәҝзә§ж–Ү件зҡ„ж ёеҝғгҖӮ
QumuloDBе®һзҺ°е®һж—¶еҸҜи§ҶеҸҠжҺ§еҲ¶
QF2и®ҫи®ЎзҗҶеҝөдёҚд»…д»…жҳҜеӯҳеӮЁж–Ү件数жҚ®пјҢд№ҹеё®еҠ©дҪ е®һж—¶з®ЎзҗҶдҪ зҡ„ж•°жҚ®е’Ңз”ЁжҲ·гҖӮдј з»ҹеӯҳеӮЁз®ЎзҗҶдәәе‘ҳеҸ—йҷҗдәҺзңӢдёҚи§Ғж•°жҚ®пјҢжүҖд»ҘдёҚзҹҘйҒ“ж–Ү件系з»ҹдёӯзңҹе®һеҸ‘з”ҹдәҶд»Җд№ҲгҖӮQF2зҡ„и®ҫи®ЎжҳҜзңҹжӯЈеҸҜи§Ҷзҡ„пјҢиҝҷдёҚз®ЎдҪ еӯҳеӮЁдәҶеӨҡе°‘ж–Ү件е’Ңзӣ®еҪ•гҖӮдҫӢеҰӮпјҢдҪ иғҪз«ӢеҚізңӢеҲ°еҗһеҗҗйҮҸеҸҳеҢ–и¶ӢеҠҝд»ҘеҸҠзғӯзӮ№гҖӮдҪ д№ҹеҸҜд»Ҙи®ҫзҪ®е®һж—¶е®№йҮҸйҷҗйўқпјҢйҒҝе…ҚдәҶеңЁдј з»ҹеӯҳеӮЁдёӯйҷҗйўқе®һзҺ°зҡ„ж—¶й—ҙејҖй”ҖгҖӮдҝЎжҒҜйҖҡиҝҮеӣҫеҪўз”ЁжҲ·жҺҘеҸЈеҫ—д»Ҙи®ҝй—®пјҢеҪ“然REST APIд№ҹеҸҜд»Ҙе®һзҺ°дҝЎжҒҜзј–зЁӢи®ҝй—®гҖӮ
QF2ж–Ү件系з»ҹзҡ„йӣҶжҲҗеҲҶжһҗзү№жҖ§иў«з§°дёәQumuloDBзҡ„组件ж”Ҝж’‘е®һзҺ°гҖӮ
еҪ“зі»з»ҹжү©е……ж—¶и§ӮеҜҹе®һж—¶еҲҶжһҗзү№жҖ§пјҢдәә们йҖҡеёёдјҡй—®е®ғжҖҺд№Ҳдјҡиҝҷд№Ҳеҝ«пјҹиҝҷйҮҢжңүдёүдёӘеҺҹеӣ гҖӮ
1гҖҒеңЁQF2ж–Ү件系з»ҹдёӯпјҢQumuloDBеҲҶжһҗжҳҜеҶ…зҪ®зҡ„并е®Ңе…ЁдёҺж–Ү件系з»ҹжң¬иә«йӣҶжҲҗпјҢдј з»ҹеӯҳеӮЁпјҢе…ғж•°жҚ®жҹҘиҜўзҡ„еӣһйҰҲжқҘиҮӘдәҺж ёеҝғж–Ү件系з»ҹд»ҘеӨ–зҡ„йқһзӣёе…ізҡ„иҪҜ件组件гҖӮ
2гҖҒQF2ж–Ү件系з»ҹдҫқжүҳB-treesпјҢQumuloDBеҲҶжһҗиғҪеӨҹдҪҝз”ЁдёҖдёӘе®һж—¶иҒҡеҗҲзҡ„еҲӣж–°зі»з»ҹпјҢдёӢйқўзҡ„з« иҠӮдјҡд»Ӣз»ҚгҖӮ
3гҖҒжңҖеҗҺпјҢQumuloDBеҲҶжһҗжҳҜеӣ дёәQF2ж–Ү件系з»ҹжҳҜдёҖдёӘжөҒзәҝеһӢи®ҫи®ЎпјҢеӣ дёәе®ғйҮҮз”ЁдәҶB-treeзҙўеј•е’ҢиҷҡжӢҹеҢ–зҡ„еҸ—дҝқжҠӨзҡ„еқ—д»ҘеҸҠSBSдәӨдә’еӨ„зҗҶгҖӮ
е…ғж•°жҚ®зҡ„е®һж—¶иҒҡеҗҲ
QF2ж–Ү件系з»ҹдёӯпјҢеғҸжүҖз”Ёеӯ—иҠӮе’Ңж–Ү件计数зҡ„е…ғж•°жҚ®жҳҜеңЁж–Ү件е’Ңзӣ®еҪ•еңЁеҲӣе»әж—¶жҲ–дҝ®ж”№ж—¶иҒҡеҗҲзҡ„пјҢиҝҷе°ұж„Ҹе‘ізқҖеӨ„зҗҶж—¶дҝЎжҒҜеҸҜд»ҘеҚіж—¶и®ҝй—®иҖҢжІЎжңүжҳӮиҙөзҡ„ж–Ү件系з»ҹtreewalks.
QumuloDBз»ҙжҢҒдёҖдёӘеҚіж—¶жӣҙж–°зҡ„е…ғж•°жҚ®жҰӮи§ҲпјҢдҪҝз”Ёж–Ү件系з»ҹзҡ„B-trees收йӣҶж–Ү件系з»ҹзҡ„жӣҙж–°дҝЎжҒҜгҖӮдёҚеҗҢзҡ„е…ғж•°жҚ®еҹҹеңЁж–Ү件系з»ҹдёӯеҲӣе»әдёҖдёӘиҷҡжӢҹзҙўеј•жқҘжҰӮиҝ°гҖӮдҪ еңЁGUIдёӯи§ҒеҲ°зҡ„жҖ§иғҪеҲҶжһҗеҹәдәҺйҮҮж ·жңәеҲ¶иў«REST APIжҠҪеҮәпјҢйҮҮж ·жңәеҲ¶жҳҜеөҢе…ҘеҲ°QF2ж–Ү件系з»ҹзҡ„гҖӮз»ҹи®Ўжңүж•Ҳзҡ„йҮҮж ·жҠҖжңҜжәҗиҮӘдәҺеҚіж—¶жӣҙж–°зҡ„е…ғж•°жҚ®жҰӮи§ҲпјҢе®ғе…Ғи®ёйҮҮж ·з®—жі•еҜ№еӨ§зӣ®еҪ•е’Ңж–Ү件ж–ҪеҠ иҫғеӨ§зҡ„жқғйҮҚгҖӮ
еңЁQF2дёӯиҒҡеҗҲе…ғж•°жҚ®йҮҮз”ЁдәҶиҮӘдёӢиҖҢдёҠе’ҢиҮӘдёҠиҖҢдёӢзҡ„ж–№жі•гҖӮ
еҪ“жҜҸдёҖдёӘж–Ү件жҲ–зӣ®еҪ•ж–°зҡ„иҒҡеҗҲе…ғж•°жҚ®жӣҙж–°ж—¶пјҢе®ғзҡ„зҲ¶зӣ®еҪ•иў«ж ҮжіЁдёәdirtyпјҢе…¶д»–зҡ„жӣҙж–°дәӢ件дёәиҝҷдёӘзҲ¶зӣ®еҪ•иҝӣиЎҢжҺ’йҳҹгҖӮз”Ёиҝҷж ·зҡ„ж–№жі•пјҢж–Ү件系з»ҹдҝЎжҒҜеңЁз©ҝи¶Ҡж ‘ж—¶иў«ж”¶йӣҶе’ҢиҒҡеҗҲгҖӮе…ғж•°жҚ®з№Ғж®–дәҺеҚ•дёӘзҡ„inodeпјҢеңЁжңҖдҪҺзҡ„еұӮзә§дёҠпјҢеңЁж•°жҚ®е®һж—¶и®ҝй—®ж—¶еҲ°иҫҫж–Ү件系з»ҹзҡ„ж №гҖӮжҜҸдёӘж–Ү件е’Ңзӣ®еҪ•зҡ„ж“ҚдҪңйғҪдёҚдјҡжјҸжҺүпјҢиҝҷдәӣдҝЎжҒҜжңҖз»Ҳз№Ғж®–еҲ°йқһеёёж ёеҝғзҡ„ж–Ү件系з»ҹдёӯгҖӮиҝҷйҮҢжҳҜдёӘдёҫдҫӢгҖӮ
е·Ұиҫ№зҡ„ж ‘иҒҡйӣҶдәҶж–Ү件е’Ңзӣ®еҪ•зҡ„дҝЎжҒҜ并еҗҲ并他们еҲ°е…ғж•°жҚ®гҖӮ然еҗҺдёәдәҶзҲ¶зӣ®еҪ•е°ҶиҜҘжӣҙж–°жҺ’е…ҘйҳҹеҲ—гҖӮдҝЎжҒҜдёҠ移пјҢд»ҺиҜҘзә§пјҲеҸ¶пјүеҲ°ж №гҖӮ
并иЎҢзҡ„д»ҺдёӢиҮідёҠз№ҒиЎҚжӣҙж–°е…ғж•°жҚ®пјҢе®ҡжңҹзҡ„д»Һж–Ү件系з»ҹйЎ¶йғЁејҖе§Ӣжү«жҸҸиҜ»еҸ–е…ғж•°жҚ®дёӯе‘ҲзҺ°зҡ„дҝЎжҒҜгҖӮеҪ“жү«жҸҸеҸ‘зҺ°жӣҙж–°зҡ„иҒҡеҗҲдҝЎжҒҜж—¶пјҢдҝ®ж•ҙиҝҷдёӘжү«жҸҸиҪ¬еҲ°дёӢдёҖдёӘеҲҶеҸүгҖӮдёҖдёӘеҒҮе®ҡжҳҜеңЁж–Ү件系з»ҹж ‘дёӯд»ҺеҪ“еүҚдҪҚзҪ®еҫҖдёӢеҲ°еҸ¶пјҲеұӮпјүпјҲеҢ…жӢ¬дәҶжүҖжңүж–Ү件е’Ңзӣ®еҪ•зҡ„еұӮжҲ–еҸ¶пјүзҡ„иҒҡеҗҲдҝЎжҒҜжҳҜе®һж—¶жӣҙж–°зҡ„пјҢдёҚйңҖиҰҒжү«жҸҸжӣҙдҪҺеұӮеҒҡжӣҙеӨҡзҡ„еҲҶжһҗгҖӮеӨ§йғЁеҲҶзҡ„е…ғж•°жҚ®жҰӮи§Ҳе·Із»Ҹиў«и®Ўз®—иҝҮпјҢзҗҶжғіжғ…еҶөдёӢпјҢжү«жҸҸд»…д»…йңҖиҰҒйҮҚж–°жҸҸиҝ°ж•ҙдёӘж–Ү件系з»ҹдёӯзҡ„дёҖе°ҸйғЁеҲҶгҖӮж•ҲжһңжҳҜиҒҡеҗҲзҡ„дёӨдёӘиҝӣзЁӢдјҡеңЁдёӯй—ҙжҹҗдёӘзӮ№зӣёйҒҮпјҢж— йңҖд»ҺдёҠиҮідёӢжЈҖзҙўж•ҙдёӘж–Ү件系з»ҹж ‘гҖӮ
йҮҮж ·е’Ңе…ғж•°жҚ®жҹҘиҜў
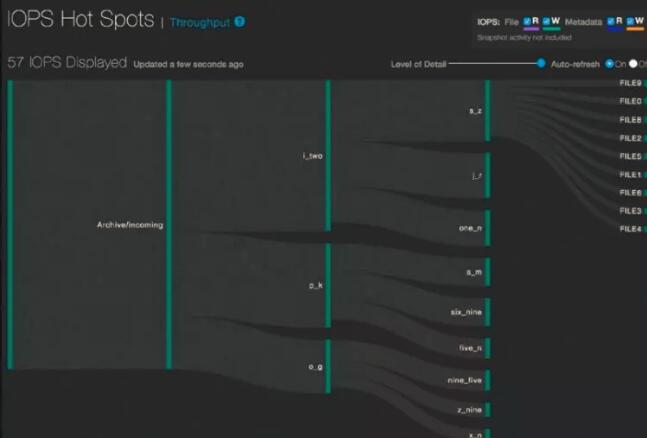
QF2е®һж—¶еҲҶжһҗзҡ„дёҖдёӘжҳҺжҳҫдҫӢеӯҗжҳҜжҖ§иғҪзғӯзӮ№жҠҘиЎЁгҖӮиҝҷжҳҜдёҖдёӘеӣҫеҪўз•ҢйқўжҲӘеұҸгҖӮ
еңЁеӨ§зҡ„ж–Ү件系з»ҹдёӯз”ЁGUIжҸҸиҝ°жҜҸдёӘеҗһеҗҗйҮҸж“ҚдҪңе’ҢIOPSжҳҜдёҚеҸҜиғҪзҡ„гҖӮеҸ–иҖҢд»Јд№ӢпјҢQumuloDBжҹҘиҜўйҮҮз”ЁжҰӮзҺҮи®әйҮҮж ·д»ҺиҖҢжҸҗдҫӣжҺҘиҝ‘жңүж•Ҳзҡ„дҝЎжҒҜгҖӮIOPSзҡ„иҜ»еҶҷж“ҚдҪңж•°гҖҒжҖ»дҪ“зҡ„IOеҗһеҗҗйҮҸжҳҜд»Һзј“еӯҳдёӯжҠҪж ·жҸҗеҸ–зҡ„пјҢиҝҷдёӘзј“еӯҳеҗ«жңү4096дёӘжқЎзӣ®пјҢе…¶еҶ…е®№ж•°з§’жӣҙж–°дёҖж¬ЎгҖӮ
иҝҷдёӘжҠҘиЎЁжҳҫзӨәзҡ„ж“ҚдҪңжҳҜеҜ№йӣҶзҫӨдә§з”ҹжңҖеӨ§еҪұе“Қзҡ„ж“ҚдҪңгҖӮиҝҷдәӣж“ҚдҪңеңЁGUIдёӯиў«иЎЁиҝ°жҲҗзғӯзӮ№пјҲhotspotsпјүгҖӮ
QF2дҪҝз”ЁжҰӮзҺҮи®әйҮҮж ·зҡ„жңүж•Ҳз»ҹи®ЎиғҪеҠӣд»…д»…еӣ дёәQumuloDBдёӯиҝһз»ӯе®һж—¶и®°еҪ•дәҶжҸҸиҝ°жҜҸдёӘзӣ®еҪ•зҡ„е…ғж•°жҚ®пјҲдҪҝз”Ёзҡ„еӯ—иҠӮж•°пјҢж–Ү件计数пјүгҖӮиҝҷжҳҜQF2й«ҳзә§иҪҜ件жҠҖжңҜзӢ¬дёҖж— дәҢзҡ„дјҳеҠҝпјҢе…¶д»–зҡ„ж–Ү件еӯҳеӮЁзі»з»ҹдёҚе…·еӨҮгҖӮ
е®һж—¶йҷҗйўқ
жӯЈеғҸе®һж—¶е…ғж•°жҚ®иҒҡеҗҲе®һзҺ°дәҶQF2зҡ„е®һж—¶еҲҶжһҗпјҢе®ғд№ҹе®һзҺ°дәҶе®һж—¶зҡ„е®№йҮҸйҷҗйўқгҖӮйҷҗйўқдҪҝеҫ—з®ЎзҗҶдәәе‘ҳеҸҜд»Ҙе®ҡд№үдёҖдёӘз»ҷе®ҡзҡ„зӣ®еҪ•еҸҜд»ҘеҚ з”Ёзҡ„з©әй—ҙе®№йҮҸгҖӮдҫӢеҰӮпјҢеҰӮжһңз®ЎзҗҶе‘ҳеҸ‘зҺ°жҹҗдёӘж— иө–з”ЁжҲ·зҡ„еӯҗзӣ®еҪ•еҚ з”Ёз©әй—ҙиҝҮеҝ«пјҢз®ЎзҗҶе‘ҳеҲҷеҸҜд»ҘеҚіж—¶йҷҗеҲ¶йӮЈдёӘз”ЁжҲ·жүҖз”Ёзӣ®еҪ•зҡ„з©әй—ҙе®№йҮҸгҖӮ
еңЁQFдёӯпјҢйҷҗйўқжҳҜеҚіж—¶йғЁзҪІзҡ„пјҢдёҚеҝ…дәӢеүҚе®ҡд№үдҫӣз»ҷгҖӮеҸҜд»Ҙе®һж—¶е®һж–Ҫе’ҢеҸҳеҢ–гҖӮдёҖдёӘйўқеӨ–зҡ„еҘҪеӨ„жҳҜйҷҗйўқи®ҫе®ҡеҲ°зӣ®еҪ•жҗ¬з§»пјҢзӣ®еҪ•жң¬иә«еҸҜд»Ҙжҗ¬з§»иҝӣжҲ–иҖ…жҗ¬з§»еҮәйҷҗйўқеҹҹгҖӮ
дёҚеғҸе…¶д»–зҡ„ж–Ү件系з»ҹпјҢQumuloйҷҗйўқдёҚйңҖиҰҒеөҢе…ҘеҲ°ж–Ү件系з»ҹеҚ·дёӯгҖӮеҸҰеӨ–пјҢQF2移еҠЁйҷҗйўқжҲ–еңЁйҷҗйўқеҹҹдёӯ移еҠЁзӣ®еҪ•пјҢдёҚдјҡеј•е…ҘиҝҮй•ҝзҡ„treewalksгҖҒдҪңдёҡи°ғеәҰгҖҒз№ҒзҗҗеӨ„зҗҶд»ҘеҸҠеӨҡжӯҘиҝӣзЁӢгҖӮQF2дёӯзҡ„йҷҗйўқеҸҜд»Ҙе®һж–ҪеҲ°д»»ж„Ҹзӣ®еҪ•пјҢз”ҡиҮіжҳҜеҘ—еҸ зҡ„зӣ®еҪ•гҖӮеҰӮжһңеӣ дёәеҘ—еҸ зҡ„зӣ®еҪ•еҺҹеӣ еҸ‘з”ҹз©әй—ҙеҲҶй…ҚдёҺеӨҡдёӘйҷҗйўқзӣёе…іпјҢжүҖжңүзҡ„йҷҗйўқеҝ…йЎ»иў«ж»Ўи¶ід»ҘдҫҝеҲҶй…ҚиҜ·жұӮзҡ„еӯҳеӮЁз©әй—ҙгҖӮ
еӣ дёәQF2дёӯйҷҗйўқйҷҗеҲ¶жҳҜеңЁзӣ®еҪ•зә§еҲ«д»Ҙе…ғж•°жҚ®ж–№ејҸи®°еҪ•дҝқеӯҳпјҢйҷҗйўқе°ұеҸҜд»ҘеңЁзӣ®еҪ•ж ‘дёӯд»»ж„ҸеұӮзә§и®ҫзҪ®гҖӮеҪ“еҶҷж“ҚдҪңеҸ‘з”ҹж—¶пјҢжүҖжңүзӣёе…ійҷҗйўқеҝ…йЎ»иў«ж»Ўи¶ігҖӮиҝҷжҳҜзЎ¬йҷҗйўқйҷҗеҲ¶гҖӮQF2е®һж—¶йҷҗйўқзҡ„зІҫзЎ®жҖ§е’Ңж•ҸжҚ·жҖ§жҳҜз”ұеҶ…зҪ®иҒҡеҗҲеҷЁиҝһз»ӯдёҚж–ӯзҡ„еҜ№жҜҸдёӘзӣ®еҪ•жүҖеҚ з©әй—ҙжҸҸиҝ°зҡ„еҚіж—¶жӣҙж–°дҝқиҜҒзҡ„гҖӮ
еҝ«з…§
еҝ«з…§дҪҝеҫ—зі»з»ҹз®ЎзҗҶе‘ҳеҜ№ж–Ү件系з»ҹжҲ–иҖ…зӣ®еҪ•еңЁд»»ж„Ҹз»ҷе®ҡж—¶й—ҙзӮ№зҡ„зҠ¶жҖҒиҝӣиЎҢдҝқжҠӨгҖӮеҰӮжһңдёҖдёӘж–Ү件жҲ–иҖ…зӣ®еҪ•иў«ж— ж„Ҹдҝ®ж”№жҲ–иҖ…еҲ йҷӨпјҢз”ЁжҲ·жҲ–зі»з»ҹз®ЎзҗҶе‘ҳеҸҜд»ҘжҒўеӨҚе…¶еҲ°дҝқеӯҳзҡ„зҠ¶жҖҒгҖӮ
QF2дёӯзҡ„еҝ«з…§пјҢжҳҜжһҒз«Ҝжңүж•Ҳе’Ңй«ҳеәҰеҸҜжү©е……зҡ„йғЁзҪІгҖӮдёҖдёӘQF2йӣҶзҫӨеҸҜд»ҘжңүеҮ д№Һж— ж•°йҮҸйҷҗеҲ¶зҡ„并еҸ‘еҝ«з…§пјҢеҗҢж—¶еҝ«з…§дёҚеёҰжқҘжҖ§иғҪе’Ңе®№йҮҸзҡ„дёӢйҷҚгҖӮ
еҝ«з…§зҡ„йғЁзҪІеҺҹзҗҶжҳҜout-of-placeblock writesгҖӮеҝ«з…§еҸ‘з”ҹеҗҢж—¶жңүеқ—иў«дҝ®ж”№ж—¶пјҢ他们被еҶҷеҲ°дёҖдёӘж–°зҡ„B-treeblocksзҡ„йӘЁе№ІдёҠгҖӮжІЎжңүеҸ‘з”ҹеҸҳеҢ–зҡ„зҺ°жңүж•°жҚ®еқ—иў«й“ҫжҺҘеҲ°иҝҷдёӘж–°зҡ„йӘЁе№ІдёҠ并且е…ұдә«гҖӮиҜҘж–°иў«дҝ®ж”№зҡ„йӘЁе№ІеҶҷзҡ„ж–№ејҸжҳҜвҖңout ofplaceвҖқпјҢдҪҶдҫқ然й“ҫжҺҘеҲ°зҺ°жңүж•°жҚ®пјҢе…ұдә«жІЎжңүеҸ‘з”ҹеҸҳеҢ–зҡ„ж•°жҚ®еқ—гҖӮзӣҙеҲ°ж•°жҚ®иў«дҝ®ж”№жҲ–иў«еҲ йҷӨеҝ«з…§йғҪдёҚеҚ з”ЁйўқеӨ–з©әй—ҙгҖӮ
жҜ”еҰӮпјҢжҠҠдёҖдёӘ4MBзҡ„ж–Ү件еҶҷеҲ°QF2зҡ„ж–Ү件系з»ҹдёӯпјҢеҒҡдёҖдёӘеҝ«з…§гҖӮеҝ«з…§е®ҢжҲҗеҗҺпјҢжүҖеҚ з©әй—ҙе®№йҮҸд»Қ然жҳҜ4MBгҖӮ然еҗҺиҜҘж–Ү件дёӯ1MBзҡ„еҢәеҹҹеҸ‘з”ҹдәҶеҸҳеҢ–гҖӮж–°ж•°жҚ®пјҲ1MBпјүиў«еҶҷеҲ°дәҶеҲ«зҡ„дҪҚзҪ®пјҲout of placeпјүпјҢдҪҶдёҺиҜҘж–Ү件зҡ„жҙ»и·ғпјҲliveпјүзүҲжң¬зӣёе…іиҒ”гҖӮ4MBж•°жҚ®дёӯеҺҹе§Ӣзҡ„3MBж•°жҚ®еңЁжҙ»и·ғзүҲжң¬е’Ңеҝ«з…§зүҲжң¬д№Ӣй—ҙе…ұдә«гҖӮиҜҘж–Ү件зҺ°еңЁжҖ»е…ұеҚ з”Ё5MBз©әй—ҙгҖӮ
еҝ«з…§жҳҜдёҖдёӘе®үе…Ёзү№жҖ§пјҢдҝқиҜҒж–Ү件系з»ҹеҝ«йҖҹжҒўеӨҚпјҢйҒҝе…Қз”ЁжҲ·иҜҜеҲ йҷӨе’ҢиҜҜдҝ®ж”№еёҰжқҘж•°жҚ®жҚҹеӨұгҖӮжҜ”еҰӮпјҢеҰӮжһңдёҖдәӣж•°жҚ®ж„ҸеӨ–иў«еҲ йҷӨпјҢз”ЁжҲ·е°ұеҸҜд»Ҙд»Һд»ҺеүҚзҡ„еҝ«з…§дёӯжҒўеӨҚж•°жҚ®гҖӮеҚ•дёӘж–Ү件жҲ–ж•ҙдёӘзӣ®еҪ•еҖҹеҠ©дәҺжҠҠ他们жӢ·иҙқеӣһжҙ»и·ғж–Ү件系з»ҹеҫ—д»ҘжҒўеӨҚгҖӮ
еҪ“еӯҳеӮЁеҸҜз”Ёз©әй—ҙеҸҳеҫ—еҫҲе°‘ж—¶пјҢз®ЎзҗҶе‘ҳйҖҡеёёеҶіе®ҡеҲ йҷӨеҝ«з…§йҮҠж”ҫеӯҳеӮЁз©әй—ҙгҖӮеӣ дёәеҝ«з…§е…ұдә«ж•°жҚ®пјҢеҲ йҷӨеҝ«з…§йҖҡеёёдёҚдјҡеӣһ收еҲ°дёҺж•ҙдёӘж–Ү件жүҖеҚ е…ЁйғЁз©әй—ҙзӣёеҪ“зҡ„е®№йҮҸгҖӮеңЁдј з»ҹеӯҳеӮЁзі»з»ҹдёӯпјҢдәӢе®һдёҠеҫҲйҡҫзҹҘйҒ“еӣһ收дәҶеӨҡе°‘еӯҳеӮЁз©әй—ҙгҖӮ
QF2дёӯзҡ„еҝ«з…§пјҢеҲ©з”ЁеҶ…зҪ®дәҺж–Ү件系з»ҹзҡ„жҷәиғҪдјҳеҠҝпјҢз®ЎзҗҶе‘ҳиғҪеӨҹи®Ўз®—еҮәеҲ йҷӨеҝ«з…§еҗҺиғҪеӣһ收зҡ„е®һйҷ…з©әй—ҙе®№йҮҸгҖӮ
иҝһз»ӯеӨҚеҲ¶
QF2жҸҗдҫӣдәҶжЁӘи·ЁдёҚеҗҢеӯҳеӮЁйӣҶзҫӨд№Ӣй—ҙзҡ„иҝһз»ӯеӨҚеҲ¶иғҪеҠӣпјҢж— и®әиҝҷдәӣйӣҶзҫӨжҳҜжң¬ең°йғЁзҪІиҝҳжҳҜе…¬жңүдә‘йғЁзҪІгҖӮдёҖж—ҰеңЁжәҗйӣҶзҫӨе’Ңзӣ®ж ҮйӣҶзҫӨд№Ӣй—ҙе»әз«ӢдәҶеӨҚеҲ¶е…ізі»е№¶еҗҢжӯҘпјҢQF2е°ҶиҮӘеҠЁзҡ„дҝқжҢҒж•°жҚ®иҝһиҙҜе’ҢдёҖиҮҙгҖӮ
QF2дёӯзҡ„иҝһз»ӯеӨҚеҲ¶пјҢжҳҜеҖҹеҠ©QF2зҡ„й«ҳзә§еҝ«з…§иғҪеҠӣзЎ®дҝқж•°жҚ®еүҜжң¬зҡ„дёҖиҮҙжҖ§гҖӮжңүдәҶQF2зҡ„еҝ«з…§пјҢзӣ®ж ҮйӣҶзҫӨдёҠзҡ„дёҖдёӘеүҜжң¬еӨҚеҲ¶жҹҗдёӘзІҫзЎ®зһ¬й—ҙжәҗзӣ®еҪ•зҡ„зҠ¶жҖҒгҖӮQF2зҡ„еӨҚеҲ¶е…ізі»дёәдәҶжңҖеӨ§зҡ„зҒөжҙ»жҖ§еҸҜд»Ҙе»әз«ӢеңЁжҜҸдёӘзӣ®еҪ•зҡ„еҹәзЎҖдёҠгҖӮ
QumuloеҲ©з”ЁжҷәиғҪз®—жі•з®ЎзҗҶеӨҚеҲ¶пјҢжүҖд»ҘжІЎжңүеҝ…иҰҒз®ЎзҗҶе‘ҳд»Ӣе…ҘгҖӮQF2зҡ„еӨҚеҲ¶йў‘зҺҮеҸ–еҶідәҺеҜ№ж•ҙдёӘйӣҶзҫӨжҖ§иғҪжІЎжңүиҙҹйқўеҪұе“Қзҡ„е®һйҷ…жғ…еҶөгҖӮQF2дёӯзҡ„иҝһз»ӯеӨҚеҲ¶зҺ°еңЁжҳҜеҚ•еҗ‘ејӮжӯҘзҡ„пјӣе°ұжҳҜиҜҙжңүдёҖдёӘжәҗе’ҢдёҖдёӘеҸӘиҜ»зҡ„зӣ®ж ҮгҖӮжәҗзӣ®еҪ•зҡ„еҸҳеҢ–иў«ејӮжӯҘзҡ„еӨҚеҲ¶еҲ°зӣ®ж ҮдёҠгҖӮ
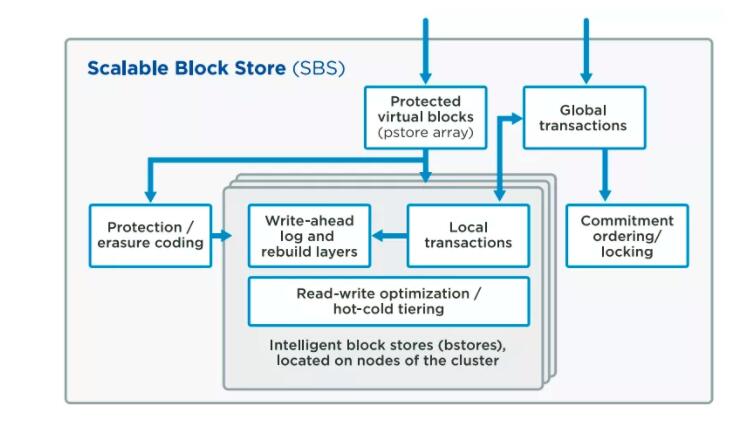
Qumulo ScalableBlock Store (SBS)
зҺ°еңЁжҲ‘们зңӢдёҖдёӢQF2ж–Ү件系з»ҹзҡ„еҶ…йғЁпјҢQF2еңЁSBSдёӯзҡ„еҲҶеёғејҸеқ—з®ЎзҗҶзҡ„зҡ„й«ҳзә§зӯ–з•ҘгҖӮдёӢйқўжҳҜдёҖдёӘжҰӮи§ҲгҖӮ
SBSжҸҗдҫӣдёҖдёӘеҸ—дҝқжҠӨзҡ„еӯҳеӮЁеқ—зҡ„дј иҫ“иҷҡжӢҹеұӮгҖӮеҸ–д»ЈдәҶзі»з»ҹдёӯж–Ү件еҝ…йЎ»й…ҚзҪ®иҮӘе·ұзҡ„дҝқжҠӨжЁЎејҸпјҢж•°жҚ®дҝқжҠӨи®ҫзҪ®еңЁж–Ү件系з»ҹдёӢйқўпјҢд№ҹе°ұжҳҜиҜҙеқ—еұӮгҖӮ
QF2еҹәдәҺеқ—зҡ„дҝқжҠӨжңәеҲ¶пјҢз”ұSBSе®һзҺ°пјҢдёәPBж•°жҚ®зҺҜеўғе’Ңж··еҗҲж–Ү件е°әеҜёиҙҹиҪҪжҸҗдҫӣеҮәдј—зҡ„жҖ§иғҪгҖӮ
SBSзҡ„дјҳеҠҝжңүеҫҲеӨҡпјҢе…¶дёӯеҢ…жӢ¬пјҡ
зЈҒзӣҳеӨұж•Ҳжғ…еҶөдёӢзҡ„еҝ«йҖҹйҮҚжһ„ж—¶й—ҙ
йҮҚжһ„ж“ҚдҪңж—¶жҢҒз»ӯзҡ„жӯЈеёёж–Ү件ж“ҚдҪңиғҪеҠӣ
常规ж–Ү件еҶҷж“ҚдҪңе’ҢйҮҚжһ„ж—¶еҸ‘з”ҹзҡ„еҶҷж“ҚдҪңжңүз«һдәүж—¶ж— жҖ§иғҪиЎ°еҮҸ
еӨ§ж–Ү件е°Ҹж–Ү件жңүзӣёеҗҢзҡ„еӯҳеӮЁж•ҲзҺҮ
еҸҜз”Ёз©әй—ҙзҡ„зІҫзЎ®жҠҘиЎЁ
й«ҳж•Ҳдј иҫ“пјҲдәӨжҳ“пјүе…Ғи®ёQF2йӣҶзҫӨжү©еұ•иҮіж•°зҷҫиҠӮзӮ№
еҶ…зҪ®зҡ„еҶ·зғӯж•°жҚ®еҲҶеұӮжҠҖжңҜе®һзҺ°дәҶеҪ’жЎЈеӯҳеӮЁд»·ж јй—ӘеӯҳжҖ§иғҪгҖӮ
еҸ—дҝқжҠӨзҡ„иҷҡжӢҹеқ—
QF2йӣҶзҫӨзҡ„ж•ҙдҪ“еӯҳеӮЁе®№йҮҸжҰӮеҝөдёҠд»ҘеҚ•дёҖгҖҒеҸ—дҝқжҠӨзҡ„иҷҡжӢҹең°еқҖз©әй—ҙжқҘз»„з»ҮпјҢеҰӮеӣҫгҖӮ
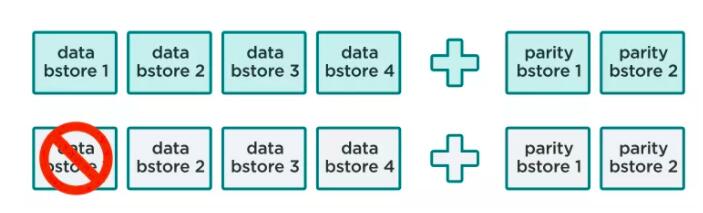
з©әй—ҙдёӯжҜҸдёӘеҸ—дҝқжҠӨзҡ„ең°еқҖеӯҳеӮЁдёҖдёӘ4Kеӯ—иҠӮзҡ„ж•°жҚ®еқ—гҖӮеҸ—дҝқжҠӨзҡ„ж„ҸжҖқжҳҜеҚідҪҝеӨҡдёӘзЈҒзӣҳеҸ‘з”ҹж•…йҡңпјҢжүҖжңүзҡ„ж•°жҚ®еқ—йғҪжҳҜеҸҜжҒўеӨҚзҡ„гҖӮ
ж•ҙдёӘж–Ү件系з»ҹй©»з•ҷеңЁSBSжҸҗдҫӣзҡ„еҸ—дҝқжҠӨзҡ„иҷҡжӢҹең°еқҖз©әй—ҙдёӯпјҢеҢ…жӢ¬з”ЁжҲ·ж•°жҚ®пјҢж–Ү件е…ғж•°жҚ®пјҢзӣ®еҪ•з»“жһ„пјҢеҲҶжһҗдҝЎжҒҜпјҢй…ҚзҪ®дҝЎжҒҜзӯүгҖӮжҚўеҸҘиҜқиҜҙпјҢеҸ—дҝқжҠӨзҡ„еӯҳеӮЁз©әй—ҙжү®жј”дәҶж–Ү件系з»ҹе’Ңи®°еҪ•еңЁеқ—и®ҫеӨҮдёҠзҡ„еҹәдәҺеқ—зҡ„ж•°жҚ®д№Ӣй—ҙзҡ„жҺҘеҸЈи§’иүІгҖӮиҝҷдәӣи®ҫеӨҮеҸҜиғҪжҳҜз”ұSSDе’ҢHDDзӣёз»“еҗҲжҲ–иҖ…е…¬жңүдә‘дёӯзҡ„еқ—еӯҳеӮЁиө„жәҗеҪўжҲҗзҡ„иҷҡжӢҹзЈҒзӣҳгҖӮ
еҝ…йЎ»и®°дҪҸпјҢеҸ—дҝқжҠӨең°еқҖз©әй—ҙдёӯзҡ„еқ—жҳҜеҲҶеёғдәҺжүҖжңүйӣҶзҫӨиҠӮзӮ№дёӯжҲ–иҖ…QF2йӣҶзҫӨе®һдҫӢдёӯзҡ„гҖӮ然иҖҢпјҢQF2ж–Ү件系з»ҹзңӢи§Ғзҡ„д»…д»…жҳҜе…ЁдҝқжҠӨеқ—зҡ„зәҝжҖ§йҳөеҲ—гҖӮ
еҹәдәҺзә еҲ з Ғзҡ„ж•°жҚ®дҝқжҠӨ
еҜ№дәҺзЈҒзӣҳж•…йҡңеј•иө·зҡ„ж•°жҚ®дёўеӨұдҝқжҠӨпјҢжҖ»жҳҜеҢ…жӢ¬жҹҗз§ҚеҪўејҸзҡ„жЁӘи·ЁеӯҳеӮЁи®ҫеӨҮзҡ„дҝЎжҒҜеҶ—дҪҷжҲ–иҖ…дҝЎжҒҜеӨҚеҲ¶гҖӮж•°жҚ®дҝқжҠӨзҡ„жңҖз®ҖеҚ•еҪўејҸжҳҜй•ңеғҸгҖӮй•ңеғҸж„Ҹе‘ізқҖжңүдёӨдёӘжҲ–еӨҡдёӘе®Ңж•ҙж•°жҚ®еүҜжң¬еӨ„дәҺдҝқжҠӨзҠ¶жҖҒгҖӮжҜҸдёӘеүҜжң¬й©»з•ҷеңЁдёҚеҗҢзҡ„зЈҒзӣҳдёҠпјҢжүҖд»ҘдёҖдёӘзЈҒзӣҳж•…йҡңеҗҺд»–жҳҜеҸҜд»ҘжҒўеӨҚзҡ„гҖӮ
й•ңеғҸе®№жҳ“йғЁзҪІпјҢдҪҶдёҺжӣҙзҺ°д»Јзҡ„дҝқжҠӨжҠҖжңҜзӣёжҜ”жңүжҳҺжҳҫзҡ„еҠЈеҠҝгҖӮй•ңеғҸдҝқжҠӨж•°жҚ®йқһеёёжөӘиҙ№еӯҳеӮЁз©әй—ҙпјҢ并且仅иғҪеә”еҜ№еҚ•дёҖзЈҒзӣҳж•…йҡңпјҢеңЁиҠӮзӮ№еҜҶеәҰе’ҢйӣҶзҫӨ规模еўһеҠ ж—¶иҝҷз§ҚдҝқжҠӨзә§еҲ«жҳҜжҳҺжҳҫдёҚеӨҹзҡ„гҖӮ
ж•°жҚ®дҝқжҠӨзҡ„е…¶д»–зӯ–з•ҘеҢ…жӢ¬RAIDStripingгҖӮRAIDдёҺд№ӢдјҙйҡҸзҡ„жҳҜжһҒеәҰеӨҚжқӮзҡ„з®ЎзҗҶиҙҹжӢ…пјҢзј“ж…ўзҡ„йҮҚжһ„ж—¶й—ҙпјҢиҝ«дҪҝз®ЎзҗҶе‘ҳеңЁдёҚеҸҜжҺҘеҸ—зҡ„жј«й•ҝйҮҚжһ„е’ҢдёҚеҸҜжҺҘеҸ—зҡ„еӯҳеӮЁеҲ©з”ЁзҺҮд№Ӣй—ҙдҪңеҮәйҖүжӢ©гҖӮ
SBSйҮҮз”Ёй«ҳж•Ҳзҡ„зә еҲ з ҒйғЁзҪІеҹәдәҺеқ—зҡ„ж•°жҚ®дҝқжҠӨгҖӮSBSз”Ёзҡ„жҳҜReed Solomonз ҒгҖӮECжҳҜжҜ”иҫғеҝ«зҡ„пјҢдёҺй•ңеғҸжҲ–иҖ…RAID StripingжҜ”иҫғиө·жқҘжӣҙеҸҜй…ҚзҪ®жӣҙиҠӮзңҒз©әй—ҙгҖӮ
зә еҲ з ҒйҮҮз”ЁеӯҳеӮЁдәҺеҲҶеёғдәҺдёҚеҗҢзҡ„зү©зҗҶд»ӢиҙЁзҡ„еҶ—дҪҷж•°жҚ®еҲҮзүҮзј–з Ғеқ—еӯҳеӮЁгҖӮECзҡ„й«ҳеҲ©з”ЁзҺҮеёҰжқҘдәҶдҪҺзҡ„жҜҸеҸҜз”ЁTBзҡ„жҲҗжң¬гҖӮ
зә еҲ з Ғзҡ„й…ҚзҪ®еҸҜд»ҘеңЁжҖ§иғҪгҖҒж•…йҡңеҸ‘з”ҹеҗҺзҡ„жҒўеӨҚж—¶й—ҙгҖҒе…Ғ许并еҸ‘ж•…йҡңж•°йҮҸзӯүжғ…еҪўдёӢдҪңеҮәеҰҘеҚҸгҖӮжң¬ж–ҮдҪҝз”Ёж Үи®°пјҲm,nпјүж ҮиҜҶзә еҲ з Ғй…ҚзҪ®пјҢmд»ЈиЎЁзү©зҗҶд»ӢиҙЁиғҪе®үе…ЁеӯҳеӮЁnдёӘз”ЁжҲ·ж•°жҚ®еқ—жҖ»зҡ„ж•°жҚ®еқ—ж•°йҮҸгҖӮиҝҷдёӘзј–з Ғд»ЈиЎЁжңҖеӨҡm-nдёӘж•°жҚ®еқ—жҚҹеқҸзҡ„жғ…еҶөдёӢдёҚдјҡеҸ‘з”ҹз”ЁжҲ·ж•°жҚ®дёўеӨұгҖӮжҚўеҸҘиҜқиҜҙпјҢnдёӘзЈҒзӣҳзҡ„з»„еҗҲеҸҜд»ҘжҒўеӨҚжүҖжңүзҡ„з”ЁжҲ·ж•°жҚ®пјҢе“ӘжҖ•дёҖдәӣзЈҒзӣҳеҗ«жңүз”ЁжҲ·ж•°жҚ®гҖӮиҝҷз§Қзј–з Ғзҡ„жңүж•ҲзҺҮеҸҜд»Ҙз”Ёn/mжқҘи®Ўз®—пјҢжҲ–иҖ…з”ЁжҲ·ж•°жҚ®еқ—ж•°йҷӨд»Ҙе…ЁйғЁж•°жҚ®еқ—ж•°гҖӮ
ECз”ЁдёҫдҫӢзҡ„ж–№ејҸеҸҠе…¶е®№жҳ“зҗҶи§ЈпјҢиҝҷжҳҜдёҖдёӘпјҲ3пјҢ2пјүзј–з ҒгҖӮ
дёҖдёӘAпјҲ3пјҢ2пјүзј–з ҒйңҖиҰҒдёүдёӘеқ—пјҲm=3пјүпјҢй©»з•ҷеңЁдёүдёӘжңүеҢәеҲ«зҡ„зү©зҗҶи®ҫеӨҮдёҠпјҢд»ҘдҝқиҜҒе®үе…Ёзҡ„еӯҳж”ҫдёӨдёӘеқ—(n=2)гҖӮе…¶дёӯзҡ„дёӨдёӘж•°жҚ®еқ—еӯҳж”ҫз”ЁжҲ·ж•°жҚ®е№¶иў«дҝқжҠӨпјҢ第дёүдёӘеқ—еҸ«еҘҮеҒ¶ж ЎйӘҢеқ—гҖӮеҘҮеҒ¶ж ЎйӘҢеқ—зҡ„еҶ…е®№з”Ёзә еҲ з Ғз®—жі•и®Ўз®—еҫ—еҮәгҖӮе°Ҫз®ЎиҝҷжҳҜдёҖдёӘжһҒе…¶з®ҖеҚ•зҡ„ж–№жЎҲпјҢд№ҹжҜ”й•ңеғҸжңүж•Ҳ вҖ“ жҜҸдёӨдёӘж•°жҚ®еқ—д»…д»…еҶҷдёҖдёӘеҘҮеҒ¶ж ЎйӘҢеқ—гҖӮеңЁдёҖдёӘпјҲ3пјҢ2пјүзј–з ҒдёӯпјҢеҗ«жңүдёүдёӘеқ—дёӯд»»ж„ҸдёҖдёӘзҡ„зЈҒзӣҳеҮәзҺ°ж•…йҡңпјҢеңЁ1е’Ң2дёӨдёӘеқ—дёӯзҡ„з”ЁжҲ·ж•°жҚ®жҳҜе®үе…Ёзҡ„гҖӮ
д»–зҡ„е·ҘдҪңеҺҹзҗҶжҳҜпјҢеҰӮжһңж•°жҚ®еқ—1жҳҜеҸҜз”Ёзҡ„пјҢйӮЈд№Ҳе°ұз®ҖеҚ•зҡ„иҜ»еҸ–е®ғгҖӮеҜ№дәҺж•°жҚ®еқ—2еҗҢж ·йҖӮз”ЁгҖӮ然иҖҢпјҢеҰӮжһңж•°жҚ®еқ—1ж•…йҡңпјҢECзі»з»ҹиҜ»еҸ–ж•°жҚ®еқ—2е’ҢеҘҮеҒ¶ж ЎйӘҢеқ—并дҪҝз”ЁReed-Solomonз Ғж–№зЁӢејҸйҮҚжһ„еҮәж•°жҚ®еқ—1зҡ„еҖјпјҲиҝҷдёӘзү№е®ҡзҡ„дҫӢеӯҗе°ұжҳҜз®ҖеҚ•ејӮжҲ–иҝҗз®—пјүгҖӮзӣёеҗҢзҡ„пјҢеҰӮжһңж•°жҚ®еқ—2й©»з•ҷзҡ„зЈҒзӣҳж•…йҡңпјҢзі»з»ҹиҜ»еҸ–ж•°жҚ®еқ—1е’ҢеҘҮеҒ¶ж ЎйӘҢеқ—гҖӮSBSе°ҶзЎ®дҝқж•°жҚ®еқ—й©»з•ҷеңЁдёҚеҗҢзҡ„зү©зҗҶзЈҒзӣҳдёҠжүҖд»Ҙзі»з»ҹиғҪеҗҢж—¶иҜ»еҸ–иҝҷдәӣеқ—гҖӮ
дёҖдёӘпјҲ3пјҢ2пјүзј–з Ғзҡ„е®№йҮҸж•ҲзҺҮжҳҜ2/3пјҲn/mпјүпјҢжҲ–иҖ…жҳҜ67%гҖӮд»Һж•°жҚ®еӯҳеӮЁи§’еәҰиҜҙжҜ”50%ж•ҲзҺҮзҡ„й•ңеғҸиҰҒеҘҪпјҢпјҲ3пјҢ2пјүзј–з Ғд»…д»…иғҪйҳІиҢғеҚ•зӣҳж•…йҡңгҖӮ
еңЁQF2дёӯжңҖе°Ҹзҡ„зј–з Ғи®ҫзҪ®жҳҜпјҲ6пјҢ4пјүпјҢжҜ”й•ңеғҸжЁЎејҸеӨҡеӯҳеӮЁ1/3зҡ„з”ЁжҲ·ж•°жҚ®пјҢдҪҶеҸҜд»Ҙе…Ғи®ёдёӨеқ—зЈҒзӣҳеҗҢж—¶ж•…йҡңгҖӮе“ӘжҖ•еҢ…еҗ«з”ЁжҲ·ж•°жҚ®зҡ„дёӨдёӘж•°жҚ®еқ—еӨұж•ҲпјҢзі»з»ҹд»Қ然иғҪеӨҹиҜ»еҸ–дёӨдёӘж•°жҚ®еқ—е’ҢдёӨдёӘеҘҮеҒ¶ж ЎйӘҢеқ—жқҘжҒўеӨҚдёўеӨұзҡ„ж•°жҚ®гҖӮ
жЁӘи·ЁиҠӮзӮ№зҡ„еҸ—дҝқжҠӨзҡ„иҷҡжӢҹеқ—зҡ„еҲҶеёғ
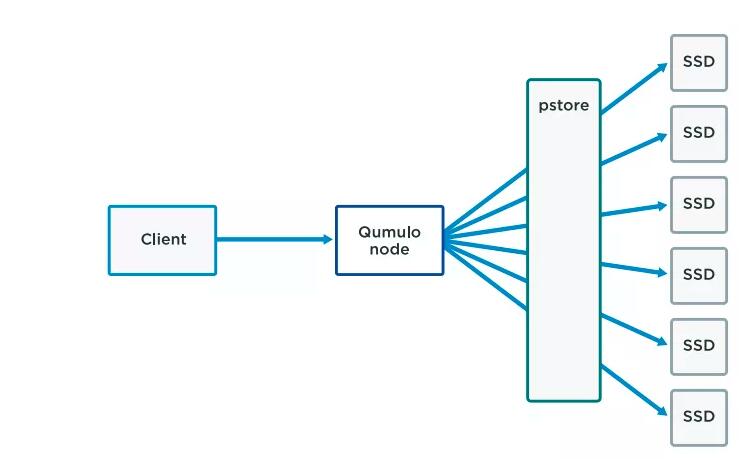
еңЁECзі»з»ҹдёӯеҜ№жө·йҮҸеҸҜжү©е……зҡ„иғҪеҠӣжңүеҫҲеӨҡе®һйҷ…зҡ„иҖғиҷ‘гҖӮдёәдәҶеҶҷйңҖиҰҒзҡ„еҘҮеҒ¶иҫғеҝ«зҡ„иҝҮзЁӢжӣҙе®№жҳ“пјҲд»ҘеҸҠзЈҒзӣҳж•…йҡңжҒўеӨҚж•°жҚ®пјүпјҢSBSжҠҠ4Kеқ—зҡ„иҷҡжӢҹең°еқҖз©әй—ҙеҲҶеүІеҲ°еҸ«еҒҡеҸ—дҝқжҠӨзҡ„еӯҳеӮЁдҪ“жҲ–pstoresзҡ„йҖ»иҫ‘еҲҮзүҮдёӯгҖӮ
SBSзӢ¬з«Ӣз®ЎзҗҶжҜҸдёҖдёӘpstoresпјҢиҝҷж ·дҪҝеҫ—еҸ—дҝқжҠӨзҡ„ең°еқҖз©әй—ҙдёҺзЈҒзӣҳзҡ„е…іиҒ”жңәеҲ¶жӣҙзҒөжҙ»гҖӮжүҖжңүзҡ„pstoresеӨ§е°ҸзӣёеҗҢгҖӮж•°жҚ®дҝқжҠӨе®Ңе…ЁйғЁзҪІеңЁзі»з»ҹзҡ„pstoresиҝҷдёӘзә§еҲ«гҖӮ
PstoresеҸҜд»ҘзҗҶи§ЈдёәжҳҜдёҖдёӘжҳ е°„еҸ—дҝқжҠӨиҷҡжӢҹең°еқҖз©әй—ҙиҢғеӣҙеҲ°QF2йӣҶзҫӨиҠӮзӮ№иҷҡжӢҹзЈҒзӣҳдёҠзҡ„еӯҳеӮЁиҝһз»ӯеҢәеҹҹзҡ„иЎЁж јгҖӮиҝҷдёӘиҝһз»ӯеҢәеҹҹз§°дҪңbstoresгҖӮ
PstoresеҲ°bstoresзҡ„жҳ е°„еӯҳеӮЁеңЁйӣҶзҫӨдёӯзҡ„жҜҸдёӘиҠӮзӮ№дёҠгҖӮдёәдәҶеҸҜйқ жҖ§йӣҶзҫӨиҠӮзӮ№йҮҮз”ЁPaxosзҡ„еҲҶеёғејҸз®—жі•жқҘдҝқжҢҒеғҸpstoresеҲ°bstoresжҳ е°„зӯүзҡ„е…ЁеұҖе…ұдә«е…ұиҜҶзҡ„дёҖиҮҙжҖ§гҖӮйӣҶзҫӨи®ҫзҪ®дәҶиҠӮзӮ№зҡ„д»ІиЈҒд»ҘдҝқиҜҒйӣҶзҫӨе…ій”®ж•°жҚ®з»“жһ„зҡ„е®үе…ЁгҖӮ
жҜҸдёӘbstoreдҪҝз”ЁдёҖдёӘзү№е®ҡиҷҡжӢҹзЈҒзӣҳзҡ„еҲҮзүҮпјҲд№ҹе°ұжҳҜиҜҙпјҢbstoreжҳҜдёҺзү№е®ҡзҡ„SSDе’ҢHDDеҜ№зӣёе…іиҒ”зҡ„пјүгҖӮеҪ“bstoreдёҺSSDзӣёе…ізҡ„з©әй—ҙеҠЁжҖҒеҲҶй…Қж—¶жҜҸдёӘbstoreеҲҶй…ҚеҲ°зӣёе…іHDDзҡ„иҝһз»ӯз©әй—ҙдёҠгҖӮBstoreзҡ„е…ғж•°жҚ®д№ҹе…ұеӯҳеңЁзӣёе…ізҡ„SSDдёҠгҖӮBstoreе…ғж•°жҚ®еҢ…жӢ¬еә”з”Ёдёӯзҡ„ең°еқҖдҝЎжҒҜпјҢж ҮиҜҶжҜҸдёӘжҢҮеҗ‘SSDеӯҳеӮЁзҡ„bstoreдёӯзҡ„еқ—ең°еқҖдёҺе“ӘдёӘHDDжҳ е°„зҡ„дҝЎжҒҜгҖӮ
иҜ»жҲ–еҶҷж—¶пјҢpstoreеҶіе®ҡе“ӘдёӘbstore йңҖиҰҒиў«и®ҝй—®гҖӮ
еҪ“ж–Ү件系з»ҹзҡ„дёҖдёӘе®ўжҲ·з«Ҝи§ҰеҸ‘дәҶеҶҷж“ҚдҪңпјҢе®ғеғҸдёҖдёӘеҺҹе§Ӣж•°жҚ®жөҒиҝӣе…ҘSBSгҖӮзі»з»ҹиҜҶеҲ«еҮәе“ӘдёӘbstoreжқҘеҶҷе…ҘиҝҷдёӘж•°жҚ®пјҢи®Ўз®—еҮәж ЎйӘҢж•°жҚ®пјҢжҠҠеҺҹе§Ӣж•°жҚ®е’Ңж ЎйӘҢж•°жҚ®еҗҢж—¶еҶҷе…ҘSSDsпјҢеҚідҫҝSSDsй©»з•ҷеңЁдёҚеҗҢзҡ„иҠӮзӮ№дёҠд№ҹжҳҜеҰӮжӯӨгҖӮдёҖж—Ұж•°жҚ®еҶҷе®ҢпјҢе®ўжҲ·з«Ҝе°Ҷеҫ—еҲ°еҸҚйҰҲпјҢеҶҷж“ҚдҪңе·Із»ҸеҸ‘з”ҹгҖӮ
еҗ«жңүз”ЁжҲ·ж•°жҚ®еқ—е’Ңж ЎйӘҢдҝЎжҒҜж•°жҚ®еқ—зҡ„ж•°жҚ®еқ—еҗҢж—¶иў«еҶҷе…ҘbstoresпјҢдёҖдёӘзү№е®ҡзҡ„bstoreпјҢеңЁе®ғзҡ„еӯҳжҙ»е‘ЁжңҹеҶ…пјҢиҰҒд№ҲеҢ…еҗ«з”ЁжҲ·ж•°жҚ®еқ—пјҢиҰҒд№ҲеҢ…еҗ«еҘҮеҒ¶ж ЎйӘҢж•°жҚ®еқ—пјҢдҪҶдёҚиғҪдёӨиҖ…еҗҢж—¶еҢ…еҗ«гҖӮеӣ дёәECе®һж–ҪйғЁзҪІеңЁSBSзҡ„pstoreеұӮпјҢеҗ«жңүж ЎйӘҢдҝЎжҒҜж•°жҚ®еқ—зҡ„bstoreе’Ңеҗ«жңүз”ЁжҲ·ж•°жҚ®еқ—зҡ„bstoreиҝҗдҪңеҪўејҸе®Ңе…ЁдёҖж ·гҖӮ
еҲҶй…Қз»ҷbstoreзҡ„еӯҳеӮЁе®№йҮҸеӨ§е°ҸеҸ–еҶідәҺECзҡ„е®ҡд№үгҖӮPstoreзҡ„е°әеҜёеӨ§е°ҸеүҚеҗҺдёҖиҮҙпјҢзі»з»ҹbstoreзҡ„е°әеҜёеӨ§е°Ҹдҫқзј–з ҒжңәеҲ¶иҖҢеҸҳеҢ–гҖӮдҫӢеҰӮпјҢеҰӮжһңpstoreжҳҜ70GBпјҢеңЁпјҲ6пјҢ4пјүзҡ„зј–з ҒжңәеҲ¶жғ…еҶөдёӢпјҢжҜҸдёӘbstoreеӨ§зәҰжҳҜ17.5GBпјҢд№ҹе°ұжҳҜиҜҙpstoreиў«еҲҶжҲҗдәҶ4дёӘbstoresгҖӮеҜ№дәҺпјҲ10пјҢ8пјүзҡ„зј–з ҒжңәеҲ¶жқҘиҜҙbstoreзҡ„еӨ§е°Ҹе°ҶжҳҜеүҚдҫӢзҡ„дёҖеҚҠгҖӮ
еңЁдә‘жғ…еҶөдёӢпјҢQF2йҮҮз”Ёе’Ңжң¬ең°йғЁзҪІзӣёеҗҢзҡ„ж•°жҚ®дҝқжҠӨжңәеҲ¶пјҢдҪҶжңүдёҖдёӘдҫӢеӨ–гҖӮжң¬ең°йғЁзҪІпјҢж•°жҚ®дҝқжҠӨжңәеҲ¶йңҖиҰҒйӣҶзҫӨиҮіе°‘еҢ…еҗ«4дёӘиҠӮзӮ№пјҢеңЁдә‘зҺҜеўғдёӢпјҢеҚ•иҠӮзӮ№йӣҶзҫӨд№ҹжҳҜеҸҜиғҪзҡ„пјҢеӣ дёәQF2еҸҜд»ҘдҪҝз”ЁеҶ…зҪ®зҡ„й•ңеғҸпјҢе®ғеӯҳеңЁдәҺжҜҸдёҖдёӘеј№жҖ§еӯҳеӮЁеқ—дёӯгҖӮдә‘зҺҜеўғдёӢзҡ„еҚ•иҠӮзӮ№йӣҶзҫӨйҮҮз”ЁпјҲ5пјҢ4пјүзҡ„зә еҲ з ҒжңәеҲ¶гҖӮ
еҝ«йҖҹйҮҚжһ„ж—¶й—ҙ
QF2зҡ„йҮҚжһ„ж—¶й—ҙд»Ҙе°Ҹж—¶и®ЎпјҢдёҺд№ӢеҜ№еә”дј з»ҹзҡ„еӯҳеӮЁзі»з»ҹпјҢеҚідҫҝйқўеҗ‘йқһеёёе°Ҹзҡ„ж•°жҚ®иҙҹиҪҪи®ҫи®ЎпјҢйҮҚжһ„ж—¶й—ҙд№ҹд»ҘеӨ©и®ЎгҖӮеӨ§йҮҸзҡ„ж–Ү件пјҢж··еҗҲиҙҹиҪҪпјҢдёҚж–ӯеўһеҠ зҡ„зЈҒзӣҳеҜҶеәҰйғҪеҜ№дј з»ҹеӯҳеӮЁзҡ„йҮҚжһ„ж—¶й—ҙеёҰжқҘдәҶеҚұжңәгҖӮQF2еңЁйҮҚжһ„ж—¶й—ҙж–№йқўзҡ„жҲҸеү§жҖ§дјҳеҠҝжҳҜSBSй«ҳзә§зҡ„еҹәдәҺеқ—зҡ„дҝқжҠӨзҡ„зӣҙжҺҘз»“жһңгҖӮ
еҹәдәҺеқ—зҡ„дҝқжҠӨжңәеҲ¶еңЁд»ҠеӨ©зҡ„зҺ°д»ЈиҙҹиҪҪжғ…еҶөдёӢжҳҜйқһеёёзҗҶжғізҡ„пјҢзҺ°д»ЈиҙҹиҪҪйҖҡеёёжҳҜPBж•°жҚ®пјҢзҷҫдёҮж–Ү件пјҢеҗҢж—¶жңүеҫҲеӨҡе°Ҹж–Ү件гҖӮSBSдҝқжҠӨзі»з»ҹдёҚйңҖиҰҒеҒҡиҖ—ж—¶зҡ„treewalksжҲ–иҖ…дёҖдёӘж–Ү件еҸҲдёҖдёӘж–Ү件зҡ„йҮҚжһ„ж“ҚдҪңпјҢеҸ–иҖҢд»Јд№Ӣзҡ„жҳҜпјҢйҮҚжһ„ж“ҚдҪңеҸ‘з”ҹеңЁpstoresеұӮйқўгҖӮеёҰжқҘзҡ„з»“жһңжҳҜйҮҚжһ„ж—¶й—ҙдёҚеҸ—ж–Ү件е°әеҜёеӨ§е°Ҹзҡ„еҪұе“ҚгҖӮе°Ҹж–Ү件зҡ„еӨ„зҗҶдёҺеӨ§ж–Ү件дёҖж ·й«ҳж•ҲпјҢдҝқжҠӨзҷҫдёҮж–Ү件е®Ңе…Ёй«ҳж•ҲеҸҜйқ гҖӮ
еҸҰеӨ–пјҢQF2зҡ„и®ҫи®ЎпјҢйӣҶзҫӨзҡ„规模еӨ§е°ҸдёҚдјҡеҜ№йҮҚжһ„ж—¶й—ҙеёҰжқҘиҙҹйқўеҪұе“ҚгҖӮдәӢе®һдёҠпјҢе…¶д»–зі»з»ҹзҡ„иҙҹйқўеҪұе“ҚиӮҜе®ҡеӯҳеңЁгҖӮеңЁQF2дёӯпјҢеӨ§и§„жЁЎйӣҶзҫӨзҡ„йҮҚжһ„ж—¶й—ҙиҝҳиҰҒеҝ«дәҺе°Ҹ规模йӣҶзҫӨгҖӮеҺҹеӣ е°ұжҳҜSBSеңЁж•ҙдёӘйӣҶзҫӨдёӯзҡ„иҠӮзӮ№дёҠеҲҶж•ЈдәҶйҮҚжһ„зҡ„и®Ўз®—иҙҹиҪҪгҖӮиҠӮзӮ№и¶ҠеӨҡпјҢйҮҚжһ„ж—¶жҜҸдёӘиҠӮзӮ№иҰҒеҒҡзҡ„е·ҘдҪңе°ұи¶Ҡе°‘гҖӮ
дј з»ҹеӯҳеӮЁзі»з»ҹиҫғй•ҝж—¶й—ҙзҡ„йҮҚжһ„дјҡеёҰжқҘйҮҚжһ„ж—¶е…¶д»–зЈҒзӣҳж•…йҡңеёҰжқҘзҡ„е·ЁеӨ§йЈҺйҷ©гҖӮжҚўеҸҘиҜқиҜҙпјҢиҫғй•ҝж—¶й—ҙзҡ„йҮҚжһ„еҜ№дәҺеҸҜйқ жҖ§жқҘиҜҙжңүе·ЁеӨ§зҡ„иҙҹйқўеҪұе“ҚгҖӮе…ёеһӢзҡ„жғ…еҶөжҳҜпјҢз®ЎзҗҶдәәе‘ҳз”ЁиҝҮеҲҶй…Қзҡ„ж–№жі•жқҘиЎҘеҒҝпјҲеўһеҠ ж•°жҚ®еҶ—дҪҷеәҰйҷҚдҪҺеӯҳеӮЁж•ҲзҺҮпјүгҖӮQF2еҝ«йҖҹзҡ„йҮҚжһ„ж—¶й—ҙпјҢз®ЎзҗҶе‘ҳиғҪеӨҹдҝқиҜҒ他们зҡ„ж•°жҚ®дёўеӨұж—¶й—ҙзӘ—еҸЈпјҲMTTDLпјҡMean Time To Data Lossпјүзӣ®ж ҮиҖҢдёҚеҝ…еҒҡеҮәеҫҲеӨ§зҡ„еҶ—дҪҷд»Јд»·пјҢеҚіиҠӮзңҒж—¶й—ҙд№ҹиҠӮзңҒй’ұгҖӮ
Pstoresзҡ„йҮҚжһ„
зЈҒзӣҳж•…йҡңж—¶пјҢpstoreдҫқ然еӯҳеңЁгҖӮе®ғд»Қ然еҸҜд»ҘиҜ»еҮәдёҺеҶҷе…ҘгҖӮ然иҖҢпјҢдёҖдәӣpstoresдјҡжңүдёўеӨұжҲ–жҚҹжҜҒзҡ„bstoresгҖӮиҝҷдәӣpstoresиў«з§°дёәйҷҚзә§пјҲdegradedпјүpstoresгҖӮжӯЈжҳҜеӣ дёәECпјҢдҪ иғҪеӨҹиҝһз»ӯзҡ„иҜ»еҸ–иҝҷдәӣйҷҚзә§зҡ„pstoresпјҢдҪҶжҳҜиҝҷдәӣж•°жҚ®дёҚеҶҚжҳҜе…Ёж–№дҪҚеҸ—дҝқжҠӨзҡ„пјҢжҚўеҸҘиҜқиҜҙпјҢеңЁз¬¬дёҖж¬Ўж•…йҡңж—¶пјҢдҪ д»Қ然жӢҘжңүж•°жҚ®зҡ„е®Ңж•ҙжҖ§дҪҶжҳҜжҳҜдёҖдёӘзЈҒзӣҳжҺҘиҝ‘дәҶж•°жҚ®дёўеӨұгҖӮ
йҮҚж–°дҝқжҠӨж•°жҚ®пјҢзі»з»ҹеңЁдёҖдёӘжҺҘдёҖдёӘзҡ„pstoreеұӮйқўдёҠйҮҚжһ„й©»з•ҷеңЁеӨұж•ҲзЈҒзӣҳдёҠзҡ„bstoresпјҲдёҚжҳҜдј з»ҹRAIDз»„дёӯдёҖдёӘжҺҘдёҖдёӘзҡ„ж–Ү件еұӮйқўпјүгҖӮSBSйў„з•ҷдәҶдёҖдёӘе°Ҹзҡ„йўқеӨ–зЈҒзӣҳз©әй—ҙе®һзҺ°иҜҘж“ҚдҪңгҖӮиҝҷдёӘеҸ«еҒҡеӨҮз”Ёе“ҒпјҲsparingпјүгҖӮ
既然全еұҖpstoreеҲ°bstoreзҡ„жҳ е°„ж¶өзӣ–дәҶдёҺbstoreзӣёе…іиҒ”зҡ„иҷҡжӢҹзЈҒзӣҳзҡ„IDпјҢиҝҷдёӘдҝЎжҒҜе°ұиғҪз®ҖеҚ•зҹҘйҒ“еҪ“дёҖдёӘзү№е®ҡзЈҒзӣҳж•…йҡңж—¶е“ӘдёӘpstoreйңҖиҰҒеӨ„зҗҶгҖӮ既然иҝҷдёӘжҳ е°„жҠҠpstoreдёҺbstoreзӣёе…іиҒ”дё”ж•°жҚ®йҮҸи¶іеӨҹе°Ҹ并驻з•ҷеңЁжҜҸдёӘиҠӮзӮ№зҡ„еҶ…еӯҳдёӯпјҢйӣҶзҫӨиҠӮзӮ№е°ұиғҪеҝ«йҖҹзҝ»иҜ‘д»ҺpstoreеҲ°bstoreзҡ„иҷҡжӢҹж•°жҚ®еқ—зҡ„ең°еқҖгҖӮ
еңЁйҮҚжһ„зҡ„иҝҮзЁӢдёӯпјҢSBSйЎәеәҸиҜ»еҶҷbstoresгҖӮ既然bstoresеңЁзЈҒзӣҳдёҠжҳҜиҝһз»ӯеҲҶеёғзҡ„пјҢйҷҚзә§pstoresе°ұиғҪеӨҹеҝ«йҖҹйҮҚжһ„гҖӮйЎәеәҸж“ҚдҪңжҜ”еҫҲеӨҡе°ҸIOзҡ„ж“ҚдҪңиҰҒеҝ«еҫҲеӨҡпјҢе°ҸIOж“ҚдҪңеҫҲж…ўд№ҹиғҪйҖ жҲҗзЈҒзӣҳз«һдәүгҖӮSBSзҡ„йҮҚжһ„иҝҮзЁӢйқһеёёй«ҳж•Ҳ вҖ“ йҮҚжһ„иҝҮзЁӢдёӯе…іиҒ”еҲ°зҡ„зЈҒзӣҳдёҖж¬ЎеҸӘжңүдёҖдёӘиҜ»жҲ–иҖ…еҶҷзҡ„ж•°жҚ®жөҒгҖӮдёҚйңҖиҰҒйҡҸжңәIOгҖӮеҸҰеӨ–пјҢbstoresд№ҹи¶іеӨҹе°ҸжүҖд»ҘйҮҚж–°дҝқжҠӨж“ҚдҪңжҳҜй«ҳж•Ҳзҡ„еҲҶеҸ‘еҲ°ж•ҙдёӘйӣҶзҫӨзҡ„гҖӮ
常规ж–Ү件ж“ҚдҪңдёҚеҸ—йҮҚжһ„еҪұе“Қ
еңЁдј з»ҹж–Ү件系з»ҹдёӯпјҢй”ҒжңәеҲ¶зҡ„з«һдәүеҪұе“ҚйҮҚжһ„ж—¶й—ҙ并йҖ жҲҗйҮҚжһ„ж—¶ж–Ү件系з»ҹжҖ§иғҪдёӢйҷҚгҖӮиҝҷжҳҜеӣ дёәиҝҷдәӣж–Ү件ж“ҚдҪңдёҺйҮҚжһ„/йҮҚдҝқжҠӨзҡ„зәҝзЁӢеӯҳеңЁз«һдәүгҖӮQF2йҮҮз”ЁдәҶеёҰжңүзӢ¬з«Ӣй”ҒжңәеҲ¶зҡ„еҶҷж“ҚдҪңеҲҶеұӮжҠҖжңҜжүҖд»ҘйҮҚжһ„ж“ҚдҪңдёҺ常规ж–Ү件系з»ҹзҡ„ж“ҚдҪңжІЎжңүз«һдәүе’ҢеҶІзӘҒгҖӮ
иҝҗиЎҢиҝҷдәӣеҶҷж“ҚдҪңпјҢзі»з»ҹеҜ№йҷҚзә§pstoreеўһеҠ дәҶдёҖеұӮиҷҡжӢҹbstoreгҖӮиҝҷиў«з§°д№ӢдёәвҖңpushing a layerвҖқгҖӮеҶҷж“ҚдҪңиҝӣе…ҘиҝҷдёҖж–°зҡ„bstoresеұӮиҖҢиҜ»ж“ҚдҪңеҲҷз»“еҗҲдәҶжҜҸдёҖеұӮзҡ„дҝЎжҒҜгҖӮиҝҷйҮҢжҳҜдёҖдёӘзӨәдҫӢгҖӮ
ж–°зҡ„еҶҷж“ҚдҪңиҝӣе…ҘеҲ°дёҠеұӮзҡ„bstoresгҖӮдёҖдёӘиҜ»ж“ҚдҪңеҲҷеҖҹеҠ©ECз®—жі•з»“еҗҲдәҶжқҘиҮӘдёҠеұӮе’ҢдёӢеұӮзҡ„дҝЎжҒҜгҖӮдёҖж—Ұbstoreзҡ„йҮҚжһ„е®ҢжҲҗиҝҷдёӘpushеұӮе°ұдјҡж¶ҲеӨұгҖӮиҝҷдәӣеұӮжҳҜз”ұSBSеӨ„зҗҶзі»з»ҹзҡ„еӨҡдёӘ组件д»ҘдёҖз§Қж— йҳ»еЎһзҡ„ж–№ејҸжһ„е»әжҲҗзҡ„гҖӮ
е°Ҹж–Ү件дёҺеӨ§ж–Ү件дёҖж ·й«ҳж•Ҳ
еӣ дёәQF2ж–Ү件系з»ҹйҮҮз”ЁдәҶеҹәдәҺж•°жҚ®еқ—зҡ„дҝқжҠӨпјҢе°Ҹж–Ү件зҡ„еӨ„зҗҶдёҺеӨ§ж–Ү件зҡ„еӨ„зҗҶжңүзӣёеҗҢзҡ„ж•ҲзҺҮгҖӮ他们иғҪдёҺе…¶д»–ж–Ү件дёҖиө·е…ұдә«жқЎеёҰпјҲstripsпјүпјҢ并еҗҢж—¶е…ұдә«дҝқжҠӨгҖӮжҜҸдёӘж–Ү件йғҪеҢ…еҗ«ж•°жҚ®еқ—пјҢиҮіе°‘дёҖдёӘinodeеқ—пјҢд»ҘеҸҠеҝ…йЎ»зҡ„е…¶д»–зҡ„еқ—гҖӮйқһеёёе°Ҹзҡ„ж–Ү件жҳҜinlinedеҲ°inodeеқ—дёӯзҡ„гҖӮжң¬зі»з»ҹжҳҜйҮҮз”ЁдәҶ4KеӨ§е°Ҹзҡ„ж•°жҚ®еқ—пјҢжүҖжңүзҡ„еқ—йғҪд»Ҙзі»з»ҹзҡ„дҝқжҠӨжҜ”зҺҮеҫ—еҲ°дҝқжҠӨгҖӮ
еёҰжңүе°Ҹж–Ү件зҡ„QF2ж–Ү件系з»ҹзҡ„ж•ҲзҺҮжҳҜзӣёиҫғдәҺдј з»ҹеӯҳеӮЁзі»з»ҹзҡ„дёҖдёӘе·ЁеӨ§дјҳеҠҝпјҢ他们еҜ№е°Ҹж–Ү件е’Ңзі»з»ҹе…ғж•°жҚ®йҮҮеҸ–зҡ„жҳҜж— ж•Ҳзҡ„й•ңеғҸжҠҖжңҜгҖӮ
жүҖе‘ҲзҺ°зҡ„е…ЁйғЁеӯҳеӮЁе®№йҮҸеҜ№з”ЁжҲ·ж–Ү件жқҘиҜҙйғҪжҳҜеҸҜз”Ёзҡ„
QF2з”ЁжҲ·ж–Ү件иғҪзҷҫеҲҶд№Ӣзҷҫзҡ„еҚ з”Ёе‘ҲзҺ°з©әй—ҙпјҲprovisionedпјү,иҖҢдј з»ҹscale-outеӯҳеӮЁзі»з»ҹе»әи®®д»…д»…дҪҝз”Ё80%еҲ°85%гҖӮеҹәдәҺеқ—дҝқжҠӨзҡ„QF2дёҚйңҖиҰҒйў„з•ҷз©әй—ҙпјҲuser-provisionedпјүе®һзҺ°йҮҚдҝқжҠӨпјҢиҖҢжҳҜз”ЁдёҖдёӘе°ҸйҮҸз©әй—ҙжқҘsparingпјҢиҝҷдёӘз©әй—ҙдёҚеұһдәҺз”ЁжҲ·е‘ҲзҺ°еӯҳеӮЁз©әй—ҙгҖӮдёҺд№ӢеҜ№з…§зҡ„жҳҜ常规еӯҳеӮЁзі»з»ҹйғЁзҪІдҝқжҠӨжңәеҲ¶дёҚжҳҜз”Ёеӣәе®ҡзҡ„RAIDз»„жҠҖжңҜе°ұжҳҜз”ЁеҹәдәҺж–Ү件зҡ„зә еҲ з ҒжҠҖжңҜпјҢиҝҷе°ұж„Ҹе‘ізқҖйҮҚдҝқжҠӨд№ҹеҸ‘з”ҹеңЁж–Ү件зә§еҲ«е№¶дё”йңҖиҰҒз”ЁжҲ·е‘ҲзҺ°еӯҳеӮЁз©әй—ҙжқҘе®һзҺ°ж•°жҚ®жҒўеӨҚгҖӮ
еҸҰеӨ–пјҢQF2ж–Ү件系з»ҹиғҪзІҫзЎ®жҳҫзӨәз”ЁдәҺз”ЁжҲ·ж–Ү件зҡ„еҸҜз”ЁеӯҳеӮЁз©әй—ҙгҖӮиҝҷз§ҚеҸҜйў„жөӢжҖ§жқҘжәҗдәҺеҹәдәҺеқ—зҡ„дҝқжҠӨжҠҖжңҜгҖӮдј з»ҹеӯҳеӮЁзі»з»ҹеӯҳеӮЁзҡ„дҪҝз”Ёдҫқиө–ж–Ү件зҡ„еӨ§е°ҸпјҢжүҖд»Ҙиҝҷдәӣзі»з»ҹд»…д»…иғҪжҳҫзӨәиЈёз©әй—ҙпјҲraw spaceпјү - з®ЎзҗҶе‘ҳйңҖ дј°з®—еӨҡе°‘з©әй—ҙе®һйҷ…еҸҜз”ЁгҖӮ
еҪ“жҜ”иҫғQF2е’Ңдј з»ҹзі»з»ҹж—¶пјҢйңҖиҰҒиҖғиҷ‘жҜҸдёӘзұ»еһӢзҡ„зі»з»ҹз”ЁжҲ·е‘ҲзҺ°е®№йҮҸе®һйҷ…дёҠжңүеӨҡе°‘з©әй—ҙеҸҜз”ЁгҖӮ
ж•°жҚ®еӨ„зҗҶ
еңЁSBSдёӯпјҢеҜ№еҸ—дҝқжҠӨзҡ„иҷҡжӢҹең°еқҖз©әй—ҙзҡ„иҜ»еҶҷж“ҚдҪңжҳҜеҸҜдәӨжҳ“зҡ„гҖӮиҝҷе°ұж„Ҹе‘ізқҖпјҢдҫӢеҰӮпјҢеҪ“дёҖдёӘQF2ж–Ү件系з»ҹж“ҚдҪңйңҖиҰҒдёҖдёӘеҶҷж“ҚдҪңж¶үеҸҠеҲ°еӨҡдәҺдёҖдёӘж•°жҚ®еқ—ж—¶пјҢиҜҘж“ҚдҪңе°ҶдёҚжҳҜеҶҷжүҖжңүзӣёе…іж•°жҚ®еқ—е°ұжҳҜдёҖдёӘж•°жҚ®еқ—йғҪдёҚеҶҷгҖӮеҺҹеӯҗиҜ»еҶҷж“ҚдҪңжң¬иҙЁдёҠз”ЁдәҺж•°жҚ®зҡ„дёҖиҮҙжҖ§д»ҘеҸҠеғҸж–Ү件еҚҸи®®SMBе’ҢNFSзҡ„жӯЈзЎ®йғЁзҪІе’Ңе®һзҺ°гҖӮ
дёәдәҶдјҳеҢ–жҖ§иғҪпјҢSBSеңЁдҝқиҜҒеҸҜдәӨжҳ“зҡ„дёҖиҮҙжҖ§зҡ„IOж“ҚдҪңж—¶жңҖеӨ§еҢ–зҡ„е®һзҺ°е№¶иЎҢе’ҢеҲҶеёғејҸи®Ўз®—зҡ„жҠҖжңҜгҖӮдҫӢеҰӮпјҢSBSзҡ„и®ҫи®ЎеңЁйңҖиҰҒйЎәеәҸиҖҢйқһ并иЎҢзҡ„ж“ҚдҪңж—¶йҒҝе…ҚдәҶдёІеһӢ瓶йўҲгҖӮ
SBSеӨ„зҗҶзі»з»ҹеҺҹзҗҶжқҘжәҗдәҺARIESз®—жі•жқҘе®һзҺ°ж— йҳ»еЎһеӨ„зҗҶпјҢеҢ…жӢ¬дәҶи¶…еүҚеҶҷж—Ҙеҝ—гҖҒеӣһж»ҡж“ҚдҪңж—¶зҡ„и®°еҪ•йҮҚеӨҚгҖӮ然иҖҢпјҢSBSеӨ„зҗҶзі»з»ҹзҡ„йғЁзҪІдёҺARIESжңүеҮ дёӘйҮҚиҰҒзҡ„дёҚеҗҢгҖӮ
SBSе……еҲҶеҲ©з”Ёи§ҰеҸ‘дәӨжҳ“зҡ„QF2ж–Ү件系з»ҹжҳҜеҸҜд»Ҙйў„еҲӨзҡ„дәӢе®һ вҖ“ еҮәиүІзҡ„еӯҳжҙ»зҹӯпјҢдёҺд№ӢеҜ№з…§зҡ„йҖҡз”Ёж•°жҚ®еә“еӨ„зҗҶж—¶зҡ„зӣёеҜ№еӯҳжҙ»иҫғй•ҝгҖӮдёҖдёӘеӯҳжҙ»зҹӯдәӨжҳ“зҡ„еә”з”ЁжЁЎзүҲе…Ғи®ёSBSдёәдәҶж•ҲзҺҮиғҪйў‘з№ҒиЈҒеүӘеӨ„зҗҶзҡ„ж—Ҙеҝ—гҖӮеӯҳжҙ»жңҹзҹӯзҡ„еӨ„зҗҶе®һзҺ°дәҶеҝ«йҖҹзҡ„жҢҮд»Өжү§иЎҢгҖӮ
еҸҰеӨ–пјҢSBSеӨ„зҗҶзі»з»ҹжҳҜй«ҳеәҰеҲҶеёғжү§иЎҢзҡ„иҖҢдёҚйңҖиҰҒе…ЁеұҖе®ҡд№үзҡ„пјҢжҜҸдёҖдёӘеӨ„зҗҶж—Ҙеҝ—е…ҘеҸЈARIESйЈҺж јзҡ„йЎәеәҸзј–еҸ·зҡ„е…ЁйғЁжҢҮд»Өзҡ„жү§иЎҢгҖӮеҸ–иҖҢд»Јд№Ӣзҡ„жҳҜпјҢжҜҸдёҖдёӘbstoreдёӯжң¬ең°еҢ–зҡ„ж—Ҙеҝ—йЎәеәҸеӨ„зҗҶд»ҘеҸҠе…ЁеұҖеұӮйқўдёҠдҪҝз”ЁйғЁеҲҶжҢҮд»ӨжңәеҲ¶е®һзҺ°йЎәеәҸзәҰжқҹжү§иЎҢзҡ„иҒ”еҗҲеҚҸи°ғгҖӮ
Qumulo DBйҮҮз”ЁдёӨйҳ¶ж®өй”ҒпјҲ2PLпјүеҚҸи®®йғЁзҪІз”ЁдәҺдёҖиҮҙжҖ§зҡ„дёІеһӢжҢҮд»ӨиҝҗиЎҢгҖӮдёІеһӢж“ҚдҪңеҲҶеёғеҲ°е…ЁйғЁbstoresдёӯжү§иЎҢпјҢ并且жү§иЎҢж“ҚдҪңйЎәеәҸеҸҜд»ҘйҮҚж–°жһ„йҖ иҝҷжҳҜз”ұз§Ғжңүзҡ„жҠҖжңҜжқҘдҝқиҜҒзҡ„гҖӮSBSж–№жі•зҡ„дјҳи¶ҠжҖ§жҳҜеӨ„зҗҶIOж“ҚдҪңдјҡз”ЁеҲ°з»қеҜ№жңҖе°‘ж•°йҮҸзҡ„й”Ғж“ҚдҪңпјҢеҗҢж—¶иҝҷе°ұдҪҝеҫ—QF2йӣҶзҫӨеҸҜд»Ҙжү©е……еҲ°ж•°зҷҫдёӘиҠӮзӮ№гҖӮ
еҶ·/зғӯеҲҶеұӮе®һзҺ°иҜ»/еҶҷдјҳеҢ–
SBSеҶ…зҪ®дәҶеҶ·зғӯж•°жҚ®еҲҶеұӮжҠҖжңҜд»ҘдјҳеҢ–иҜ»еҶҷжҖ§иғҪгҖӮ
жң¬ең°йғЁзҪІж—¶пјҢQF2е……еҲҶеҲ©з”ЁдәҶSSDзҡ„йҖҹеәҰдјҳеҠҝе’Ңдј з»ҹжңәжў°зӣҳзҡ„е»үд»·дјҳеҠҝгҖӮSSDй…ҚеҗҲHDDеңЁжҜҸдёӘиҠӮзӮ№дёҠеӯҳеңЁгҖӮиҝҷдёӘй…ҚеҗҲж–№жі•иў«з§°дёәиҷҡжӢҹзЈҒзӣҳгҖӮзі»з»ҹдёӯжҜҸдёӘHDDйғҪжңүдёҖдёӘиҷҡжӢҹзЈҒзӣҳгҖӮ
ж•°жҚ®жҖ»жҳҜиў«йҰ–е…Ҳиў«еҶҷеҲ°SSDдёҠгҖӮеӣ дёәиҜ»ж“ҚдҪңе…ёеһӢзҡ„жҳҜи®ҝй—®жңҖиҝ‘еҶҷе…Ҙзҡ„ж•°жҚ®пјҢSSDжҖ»жҳҜжү®жј”зј“еӯҳзҡ„и§’иүІгҖӮеҪ“SSDзҡ„з©әй—ҙеҚ з”ЁжҺҘиҝ‘80%зҡ„ж—¶еҖҷпјҢйқһйў‘з№Ғи®ҝй—®зҡ„ж•°жҚ®иў«жҺЁйҖҒеҲ°HDDдёҠгҖӮHDDдёәеӨ§е°әеҜёзҡ„ж•°жҚ®жҸҗдҫӣеӯҳеӮЁз©әй—ҙйЎәеәҸиҜ»еҶҷж“ҚдҪңгҖӮ
дә‘йғЁзҪІж—¶пјҢQF2еҖҹеҠ©еҢ№й…Қй«ҳжҖ§иғҪеқ—еӯҳеӮЁе’Ңе»үд»·дҪҺжҖ§иғҪеқ—еӯҳеӮЁдјҳеҢ–еқ—еӯҳеӮЁиө„жәҗзҡ„дҪҝз”ЁгҖӮ
зңӢдёҖдёӢдёӢеҲ—SBSзғӯеҶ·еҲҶеұӮзҡ„еӣ зҙ пјҡ
еҰӮдҪ•еҶҷе’ҢеҫҖе“ӘйҮҢеҶҷж•°жҚ®
е…ғж•°жҚ®еҫҖе“ӘйҮҢеҶҷ
ж•°жҚ®дҪ•ж—¶еӨұж•Ҳ
ж•°жҚ®еҰӮдҪ•зј“еӯҳе’ҢиҜ»еҸ–
еҲқе§ӢеҶҷ
еҜ№дёҖдёӘйӣҶзҫӨзҡ„еҶҷж“ҚдҪңпјҢдёҖдёӘе®ўжҲ·з«ҜеҸ‘йҖҒж•°жҚ®еҲ°дёҖдёӘиҠӮзӮ№гҖӮиҜҘиҠӮзӮ№йҖүеҸ–дёҖдёӘжҲ–еӨҡдёӘpstoresеӯҳж”ҫж•°жҚ®пјҢеҜ№дәҺ硬件жқҘиҜҙпјҢжҖ»жҳҜеҶҷеҲ°SSDжҲ–иҖ…дә‘зҺҜеўғдёӢзҡ„дҪҺ延иҝҹзҡ„еқ—еӯҳеӮЁиө„жәҗдёҠгҖӮпјҲеӣһжғідёҖдёӢпјҢжң¬ең°йғЁзҪІзҡ„SSDе’Ңдә‘йғЁзҪІзҡ„дҪҺ延иҝҹеқ—еӯҳеӮЁпјҢжҲ‘们зҡ„дҪҝз”Ёж–№жі•жҳҜзұ»дјјзҡ„пјүгҖӮиҝҷдәӣSSDеҲҶеёғдәҺеӨҡдёӘиҠӮзӮ№дёҠгҖӮ
жүҖжңүзҡ„еҶҷж“ҚдҪңйғҪжҳҜйқўеҗ‘SSDsпјӣSBSд»ҺжқҘдёҚзӣҙжҺҘеҶҷе…ҘHDDгҖӮеҚідҫҝжҳҜдёҖдёӘSSDе·Іиў«еҶҷж»ЎпјҢзі»з»ҹд№ҹдјҡжё…йҷӨеүҚйқўзј“еӯҳзҡ„ж•°жҚ®дёәиҝҷдәӣж–°ж•°жҚ®и…ҫеҮәз©әй—ҙгҖӮ
е…ғж•°жҚ®еӨ„зҗҶ
йҖҡеёёжқҘиҜҙпјҢе…ғж•°жҚ®еұ…дәҺSSDдёҠгҖӮж•°жҚ®е…ёеһӢзҡ„иў«еҶҷе…ҘеҲ°bstoreзҡ„дҪҺеҸҜз”Ёең°еқҖдёҠжүҖд»Ҙbstoreж•°жҚ®зҡ„еўһй•ҝжҳҜд»ҺејҖе§ӢзӣҙеҲ°еӯҳж»ЎгҖӮе…ғж•°жҚ®зҡ„еӯҳж”ҫжҳҜзӣёеҸҚзҡ„пјҢд»Һbstoreзҡ„з»“е°ҫеҫҖе®ғзҡ„ејҖе§Ӣж–№еҗ‘еўһй•ҝгҖӮиҝҷе°ұжҳҜиҜҙе…ғж•°жҚ®еңЁз”ЁжҲ·ж•°жҚ®зҡ„еҸіиҫ№гҖӮдёӢеӣҫжҳҫзӨәдәҶbstoreдёӯе…ғж•°жҚ®зҡ„еӯҳж”ҫдҪҚзҪ®гҖӮ
QF2еңЁSSDдёҠзҡ„bstoreдёӯдёәе…ғж•°жҚ®еҲҶй…ҚдәҶжңҖеӨҡдёҚеҲ°1%зҡ„з©әй—ҙ并且永久жңүж•ҲгҖӮиҝҷ1%з©әй—ҙдёӯзҡ„ж•°жҚ®ж°ёиҝңдёҚдјҡжҺЁйҖҒеҲ°HDDдёҠпјҢеҰӮжһңе…ғж•°жҚ®зҡ„еӨ§е°Ҹи¶…иҝҮ1%е°ұдјҡеӨұж•ҲпјҢдҪҶжҳҜе…ёеһӢе·ҘдҪңиҙҹиҪҪд»…жңүжҺҘиҝ‘1%зҡ„е…ғж•°жҚ®йҮҸгҖӮеҰӮжһңжІЎжңүи¶іеӨҹзҡ„е…ғж•°жҚ®йҮҸз©әй—ҙд№ҹдёҚдјҡжөӘиҙ№пјҢе…¶д»–ж•°жҚ®д№ҹеҸҜд»ҘеҚ з”ЁиҝҷдёӘз©әй—ҙгҖӮ
ж•°жҚ®еӨұж•Ҳ
еңЁдёҖдәӣе…ій”®зӮ№дёҠпјҢзі»з»ҹйңҖиҰҒжӣҙеӨҡзҡ„SSDдёҠзҡ„з©әй—ҙжүҖд»ҘдёҖдәӣж•°жҚ®дјҡеӨұж•ҲпјҢжҲ–иҖ…д»ҺSSD移еҲ°HDDгҖӮжҠҠж•°жҚ®д»ҺSSDжӢ·иҙқеҲ°HDDпјҢиҖҢеҗҺдёҖж—Ұж•°жҚ®еӯҳеҲ°дәҶHDDпјҢе°ұиў«д»ҺSSDдёҠеҲ йҷӨгҖӮ
еӨұж•Ҳж“ҚдҪңе§ӢдәҺдёҖдёӘSSDзҡ„жүҖз”Ёз©әй—ҙе·Іиҫҫ80%пјҢеҒңжӯўдәҺз©әй—ҙеҚ з”Ёиҝ”еӣһеҲ°е°ҸдәҺ80%гҖӮиҝҷдёӘ80%зҡ„й—Ёж§ӣжҳҜдёҖдёӘж‘ёзҙўеҮәжқҘзҡ„зӣ®зҡ„еңЁдәҺдјҳеҢ–жҖ§иғҪ вҖ“ SSDз©әй—ҙеҚ з”ЁеңЁ0%еҲ°80%д№Ӣй—ҙж—¶еҶҷж“ҚдҪңйқһеёёеҝ«еҗҢж—¶еӨұж•Ҳд№ҹдёҚдјҡеҮәзҺ°гҖӮ
еңЁж•°жҚ®д»ҺSSD被移еҠЁеҲ°HDDж—¶пјҢSBSдјҡдјҳеҢ–йЎәеәҸеҶҷеҲ°HDDпјҢиҝҷд№ҹжҳҜдёәдәҶдјҳеҢ–зЈҒзӣҳжҖ§иғҪгҖӮеЎ«ж»ЎеӨ§зҡ„гҖҒиҝһз»ӯзҡ„еӯ—иҠӮеҜ№еҶҷHDDжқҘиҜҙеҸҜиғҪжҳҜжңҖй«ҳж•Ҳзҡ„ж–№жі•гҖӮ
зј“еӯҳж•°жҚ®
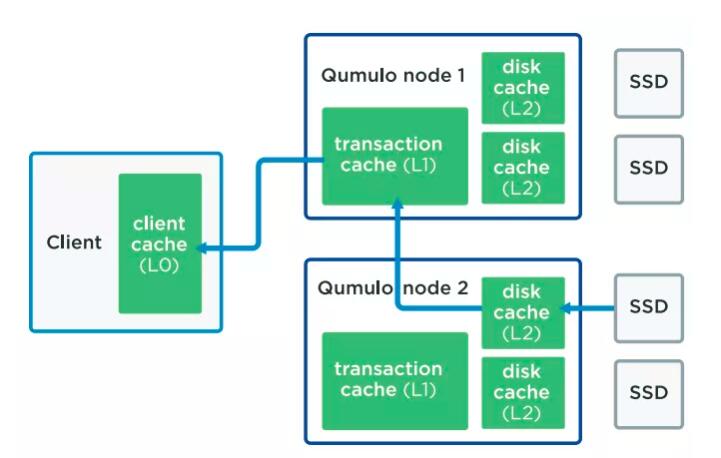
дёӢйқўзҡ„иҜҙжҳҺжҳҫзӨәдәҶжүҖжңүQF2зҡ„зј“еӯҳгҖӮжүҖжңүзҡ„з»ҝиүІйғЁеҲҶйғҪжҳҜиғҪеӯҳеӮЁж•°жҚ®зҡ„ең°ж–№пјҢе®ғж—ўеҸҜиғҪеңЁSSDдёҠпјҢд№ҹеҸҜиғҪеңЁHDDдёҠгҖӮ
QF2зҡ„IOж“ҚдҪңдҪҝз”ЁдәҶдёүз§ҚдёҚеҗҢзұ»еһӢзҡ„зј“еӯҳгҖӮе®ўжҲ·з«ҜжҖ»жҳҜдјҡжңүдёҖдәӣзј“еӯҳпјҢеӯҳеӮЁиҠӮзӮ№дёҠжңүдёӨзұ»зј“еӯҳгҖӮдёҖз§ҚжҳҜдәӨжҳ“зј“еӯҳпјҢеҸҜд»Ҙиў«и®ӨдёәжҳҜе®ўжҲ·з«ҜзӣҙжҺҘиҜ·жұӮзҡ„ж–Ү件系з»ҹж•°жҚ®гҖӮеҸҰдёҖз§Қзұ»еһӢжҳҜзЈҒзӣҳзј“еӯҳпјҢз”ЁдәҺжқҘиҮӘзЈҒзӣҳзҡ„ж•°жҚ®еқ—дҝқеӯҳеңЁеҶ…еӯҳдёӯгҖӮ
дҪңдёәдёҖдёӘдёҫдҫӢпјҢеҒҮе®ҡдёҖдёӘе®ўжҲ·з«ҜиҝһжҺҘеҲ°иҠӮзӮ№1дёҠеҗҜеҠЁдәҶдёҖдёӘж–Ү件Xзҡ„иҜ»ж“ҚдҪңгҖӮиҠӮзӮ№1еҸ‘зҺ°иҝҷдәӣж•°жҚ®еқ—й©»з•ҷеңЁиҠӮзӮ№2дёҠжүҖд»ҘзҹҘдјҡиҠӮзӮ№2жғіиҰҒиҝҷдәӣж•°жҚ®пјҢжң¬дҫӢдёӯж•°жҚ®еӯҳеӮЁеңЁиҠӮзӮ№2 зҡ„SSDдёҠгҖӮиҠӮзӮ№2иҜ»еҸ–иҜҘж•°жҚ®е№¶е°Ҷе…¶зҪ®дәҺдёҺиҝҷдёӘSSDе…іиҒ”зҡ„зЈҒзӣҳзј“еӯҳдёӯгҖӮиҠӮзӮ№2еӣһеӨҚиҠӮзӮ№1并且еҸ‘йҖҒиҝҷдёӘж•°жҚ®гҖӮжӯӨж—¶иҝҷдёӘж•°жҚ®иҝӣе…ҘиҠӮзӮ№1зҡ„дәӨжҳ“зј“еӯҳпјҢиҖҢеҗҺзҹҘдјҡе®ўжҲ·з«Ҝе®ғжңүдәҶж–Ү件Xзҡ„ж•°жҚ®гҖӮ
иҝһжҺҘиҝҷдёӘзЈҒзӣҳзҡ„иҠӮзӮ№жҳҜзЈҒзӣҳзј“еӯҳжүҖеңЁзҡ„иҠӮзӮ№гҖӮиҖҢиҝһжҺҘе®ўжҲ·з«Ҝзҡ„иҠӮзӮ№жҳҜдәӨжҳ“зј“еӯҳжүҖеңЁзҡ„иҠӮзӮ№гҖӮзЈҒзӣҳзј“еӯҳеӯҳжңүж•°жҚ®еқ—ж•°жҚ®иҖҢдәӨжҳ“зј“еӯҳеӯҳжңүе®һйҷ…ж–Ү件数жҚ®гҖӮдәӨжҳ“зј“еӯҳе’ҢзЈҒзӣҳзј“еӯҳе…ұдә«еҶ…еӯҳпјҢдҪҶжҳҜ并没жңүдёҖдёӘзү№е®ҡзҡ„ж•°йҮҸеҲҶй…Қз»ҷ他们дёӯзҡ„д»»дҪ•дёҖдёӘгҖӮ
е·Ҙдёҡж ҮеҮҶеҚҸи®®
QF2йҮҮз”ЁдәҶж ҮеҮҶзҡ„NFSv3е’ҢSMBv2.1еҚҸи®®гҖӮ
REST API
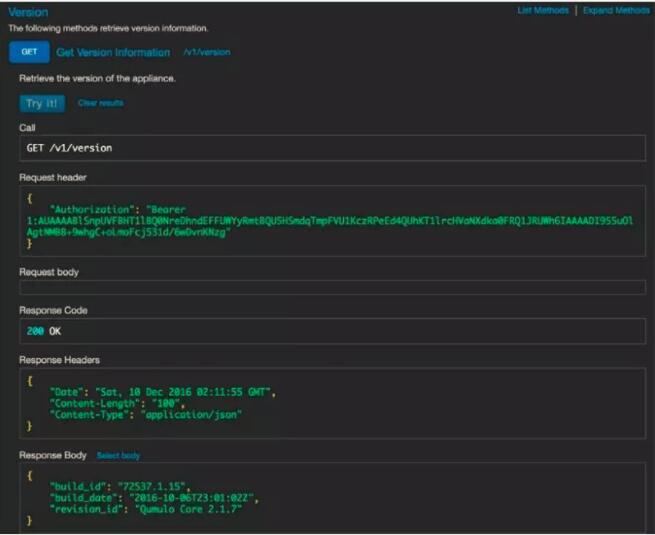
QF2еӣҠжӢ¬дәҶдё°еҜҢзҡ„REST APIгҖӮдәӢе®һдёҠQF2 GUIжүҖе‘ҲзҺ°зҡ„е…ЁйғЁдҝЎжҒҜйғҪжҳҜз”ҹжҲҗдәҺQF2 RESTAPIи°ғз”ЁгҖӮGUIдёӯзҡ„жҜҸдёӘй”®йғҪжҸҗдҫӣдёҖдёӘеҸҜз”ЁREST APIи°ғз”Ёзҡ„иҮӘжҸҸиҝ°иө„жәҗгҖӮеҸҜд»ҘеңЁиҝҗиЎҢзҡ„йӣҶзҫӨдёҠжү§иЎҢиҝҷдәӣи°ғз”ЁйӘҢиҜҒиҝҷдәӣAPIпјҢе®һж—¶жЈҖжөӢиҜ·жұӮе’Ңз»“жһңгҖӮиҝҷжҳҜдёҖдёӘдёҫдҫӢзҡ„жҲӘеұҸгҖӮ
жүҖжңүе‘ҲзҺ°зҡ„GUIеҲҶжһҗдҝЎжҒҜйғҪеҸҜд»Ҙз”ЁRESTи°ғз”ЁAPIзј–зЁӢеҸ–еӣһпјҢеӯҳеӮЁеңЁеӨ–йғЁж•°жҚ®еә“дёӯпјҢжҲ–дј йҖ’з»ҷеғҸSplunkе’ҢTableauиҝҷж ·зҡ„е…¶д»–еә”з”Ёзі»з»ҹгҖӮеӨ§йғЁеҲҶзҡ„ж–Ү件系з»ҹж“ҚдҪңд№ҹеҸҜд»Ҙз”ұREST APIиҜ·жұӮжү§иЎҢгҖӮ
з»“и®ә
жңҹеҫ…жң¬ж–ҮжҸӯзӨәдәҶQF2зҡ„еҶ…еңЁз§ҳеҜҶ并且иғҪиў«зҗҶи§ЈпјҢи®©иҜ»иҖ…жҳҺзҷҪдёәд»Җд№ҲQF2жҖ§иғҪеҮәиүІгҖҒжү©еј иғҪеҠӣи¶…ејәзҡ„еҺҹзҗҶгҖӮеҰӮжңүжӣҙеӨҡзҡ„е…ҙи¶ЈпјҢиҜ·иҒ”зі»жҲ‘们гҖӮ
е…ій”®еҶ…е®№
* ж•°жҚ®зҲҶзӮёејҸеўһй•ҝпјҢзҺ°д»Је·ҘдҪңиҙҹиҚ·жҳҜPB规模пјҢж•°еҚҒдәҝж–Ү件数йҮҸпјҢж–Ү件еӨ§е°ҸдёҚдёҖгҖӮ
* еҫҲеӨҡеӯҳеӮЁзі»з»ҹиҝҳеҹәдәҺж•°еҚҒе№ҙеүҚзҡ„жҠҖжңҜпјҢж— жі•еә”еҜ№еҪ“д»Ҡзҡ„е·ҘдҪңиҙҹиҪҪгҖӮ
* QF2жҳҜдёҖдёӘзҺ°д»ЈжҠҖжңҜеӯҳеӮЁзі»з»ҹпјҢзү№еҲ«й’ҲеҜ№еҪ“д»Ҡе·ҘдҪңиҙҹиҪҪгҖӮ
* QF2еҹәдәҺж ҮеҮҶе•Ҷ用硬件пјҢеҸҜжң¬ең°йғЁзҪІпјҢеҸҜдә‘дёӯйғЁзҪІгҖӮ
* QF2дҪҝз”ЁдәҶSSDе’ҢHDDзҡ„ж··еҗҲдҪ“зі»жһ¶жһ„гҖӮ
* QF2йҮҮз”Ёе®һйҷ…ж–Ү件系з»ҹдёӢйқўзҡ„еқ—дҝқжҠӨжңәеҲ¶гҖӮ
* QF2е…·еӨҮеҝ«йҖҹйҮҚжһ„иғҪеҠӣпјҢд»Ҙе°Ҹж—¶и®ЎпјҢжҳҜдёҡз•ҢжңҖеҝ«зҡ„гҖӮ
* з”ЁжҲ·ж–Ү件еҸҜд»ҘеҚ з”Ё100%зҡ„е‘ҲзҺ°е®№йҮҸгҖӮ
* е°Ҹж–Ү件е’ҢеӨ§ж–Ү件дёҖж ·й«ҳж•ҲгҖӮ
* ж•ҙдёӘж–Ү件系з»ҹеғҸдёҖдёӘеҚ•дёҖеҚ·дёҖж ·еӯҳеңЁгҖӮ
* QF2зҡ„ж–Ү件系з»ҹйҮҮз”ЁдәҶдёҺеӨ§еһӢеҲҶеёғејҸж•°жҚ®еә“дёҖж ·зҡ„жҠҖжңҜгҖӮ
* е®һж—¶еҲҶжһҗз»ҷеҮәж–Ү件系з»ҹеҪ“еүҚеҸ‘з”ҹдәӢ件зҡ„жҙһеҜҹеҠӣгҖӮ
* дҪҝз”Ёз©әй—ҙзҡ„зІҫзЎ®жҠҘиЎЁгҖӮ
* з®ЎзҗҶе‘ҳеҸҜе®һж–Ҫе®һж—¶йҷҗйўқгҖӮ
* з®ЎзҗҶе‘ҳжҳҺжҷ°еҲ йҷӨеҝ«з…§зҡ„зІҫзЎ®еӣһ收з©әй—ҙгҖӮ
* QF2е…·еӨҮејӮжӯҘж•°жҚ®еӨҚеҲ¶еҠҹиғҪгҖӮ
* QF2ж”ҜжҢҒNFSе’ҢSMBж ҮеҮҶеҚҸи®®пјҢдё°еҜҢзҡ„REST APIгҖӮ
ITи§ЈеҶіж–№жЎҲпјҡ ж–Ү件е…ұдә«гҖҒз§Ғжңүдә‘зӣҳгҖҒдјҒдёҡзҪ‘зӣҳ и§ЈеҶіж–№жЎҲ
еӯҳеӮЁйӣ·з”өMAS/DAS /SAN/JBOD/IPSAN ISCSI и§ЈеҶіж–№жЎҲ
дјҒдёҡзә§еӯҳеӮЁ и§ЈеҶіж–№жЎҲ
еӨҮд»Ҫ е®№зҒҫ ж•°жҚ®дҝқжҠӨзі»з»ҹ и§ЈеҶіж–№жЎҲ
йҳІеӢ’зҙўз—…жҜ’и§ЈеҶіж–№жЎҲ
NAS еә”з”ЁеңәжҷҜпјҡ
е®ҢзҫҺи§ЈеҶіж–Ү件е…ұдә«/ж–Ү件еҲҶдә«й—®йўҳпјҢжӣҝд»Јдј з»ҹж–Ү件жңҚеҠЎеҷЁ
NASзҪ‘з»ңеӯҳеӮЁ ж–Ү件NASеӯҳеӮЁ зҪ‘з»ңиҝһжҺҘеӯҳеӮЁпјҢж–Ү件еӯҳеӮЁпјҢжЁӘеҗ‘жү©еұ•зҪ‘з»ңйҷ„еҠ еӯҳеӮЁ
зҫӨжҷ–еӨҮд»ҪдёҖдҪ“жңә йҖӮз”ЁдәҺзҡ„дјҒзә§еӨҮд»ҪиҪҜ件жңүпјҡ
пјҲacronis е®үе…ӢиҜәж–Ҝ /veeamеҚ«зӣҹ/Veeam Backup & Replication /veritasеҚҺзқҝжі°/commvault ж…·еӯҡжІғеҫ· /arcserver )
PHD virtual , Nakivo, IBM spectrum protect , (TSM) HP data protector
DELL EMC Networker RecoverPoint гҖҒQuest гҖҒ veritas system recovery 18
иҷҡжӢҹж•°жҚ®дҝқжҠӨж–№жЎҲпјҡ
RTO е°ҸдәҺ2еҲҶй’ҹ
SaaSж•°жҚ®зҡ„第дёүж–№еӨҮд»Ҫ гҖҒsaasж•°жҚ®еӨҮд»ҪгҖҒSaaSеӨҮд»ҪгҖҒsalesforceж•°жҚ®еӨҮд»ҪгҖҒ Office 365ж•°жҚ®еӨҮд»ҪгҖҒGoogle Cloud G Suiteж•°жҚ®еӨҮд»Ҫ е’ҢSalesforce.comж•°жҚ®еӨҮд»Ҫ
еӨҮд»Ҫзҡ„е“Ғзұ»пјҡ
PCеӨҮд»Ҫ жңҚеҠЎеҷЁеӨҮд»Ҫ ж•°жҚ®еә“еӨҮд»Ҫ
зЈҒеёҰеә“ зҒҫеӨҮ зҒҫйҡҫеӨҮд»Ҫ дёҚеҗҢ еӨҮзӯ–з•Ҙе»әз«ӢзӢ¬з«Ӣзҡ„еӨҮд»ҪдҪңдёҡпјҢ ж–Ү件еӨҮд»Ҫ зі»з»ҹеӨҮд»Ҫ ж•°жҚ®еә“еӨҮд»Ҫ иҷҡжңәеӨҮд»Ҫ
йқһз»“жһ„еҢ–ж•°жҚ®зҡ„еӨҮд»ҪпјҢ
иҷҡжӢҹжңәеӨҮд»Ҫи§ЈеҶіж–№жЎҲпјҡ
ж— д»ЈзҗҶеӨҮд»Ҫж–№жЎҲгҖҒoVirt еӨҮд»Ҫж–№жЎҲпјҢOvirtиҷҡжӢҹеҢ–еӨҮд»ҪпјҢ
VMware vSphere еӨҮд»Ҫж–№жЎҲгҖҒCitrix XenServerеӨҮд»Ҫж–№жЎҲгҖҒRedHat RHVеӨҮд»Ҫж–№жЎҲгҖҒгҖҒOvirtеӨҮд»Ҫж–№жЎҲгҖҒгҖҒH3C CASеӨҮд»Ҫж–№жЎҲгҖҒгҖҒOpenstackеӨҮд»Ҫж–№жЎҲгҖҒгҖҒеҚҺдёә FusionSphereеӨҮд»Ҫж–№жЎҲгҖҒгҖҒдёӯ科зқҝе…ү SVMеӨҮд»Ҫж–№жЎҲгҖҒгҖҒж·ұдҝЎжңҚ HCIеӨҮд»Ҫж–№жЎҲгҖҒгҖҒдә‘е®ҸCNwareеӨҮд»Ҫж–№жЎҲгҖҒгҖҒжөӘжҪ® InCloud SphereеӨҮд»Ҫж–№жЎҲгҖҒгҖҒдёӯж Үйә’йәҹй«ҳзә§жңҚеҠЎеҷЁиҷҡжӢҹеҢ–еӨҮд»Ҫж–№жЎҲгҖҒгҖҒеҷўжҳ“жңҚеҠЎеҷЁиҷҡжӢҹеҢ–еӨҮд»Ҫж–№жЎҲгҖӮ
е…је®№еӣҪеҶ…еӨҮд»ҪиҪҜ件пјҡж•°жҚ®еӨҮд»Ҫе’ҢжҒўеӨҚйўҶеҹҹ ж•°жҚ®дҝқжҠӨи§ЈеҶіж–№жЎҲ
иӢұж–№,i2,information2,дёҠжө·иӢұж–№иҪҜ件иӮЎд»Ҫжңүйҷҗе…¬еҸё пјҢиҒ”йјҺпјҢзІҫе®№ж•°е®үпјҢйјҺз”ІпјҢзҒ«жҳҹд»“пјҢеҗҲеҠӣи®°жҳ“UPMпјҢжөӘж“ҺпјҢзҲұж•° дә‘зҘә зӣӣжҖқзқҝпјҢеӨҮд»ҪдёҺжҒўеӨҚ ,дҝЎж ёж•°з ҒпјҢж•°и…ҫ datasureгҖӮ
иҘҝеҚ—NASеӯҳеӮЁжҖ»еҲҶй”Җпјҡ
еЁҒиҒ”йҖҡ qnap, иүІеҚЎеҸёthecus,infotrendжҷ®е®ү, еҚҺиҠёasustor qsan, й“ҒеЁҒ马TerraMaster
еӣҪеӨ–еӯҳеӮЁпјҡ
EMCжҳ“е®үдҝЎпјҢnetapp ,hds. netapp,
еӯҳеӮЁеә”з”ЁиЎҢдёҡпјҡ
дјҒдёҡзә§еӯҳеӮЁ зЈҒзӣҳйҳөеҲ— йқһзј–еҪұи§ҶеҗҺжңҹеӯҳеӮЁгҖҒйӣҶзҫӨеӯҳеӮЁгҖҒиҷҡжӢҹеҢ–еӯҳеӮЁгҖҒй«ҳжҖ§иғҪдә‘и®Ўз®—еӯҳеӮЁ
еӣҪеҶ…еӯҳеӮЁпјҡ
е®Ҹжқүmacrosan , жөӘжҪ®еӯҳеӮЁinspurпјҢиҒ”жғіеӯҳеӮЁlenovoпјҢиҒ”жғіеҮҢжӢ“еӯҳеӮЁlenovo-netappпјҢжӣҷе…үеӯҳеӮЁsugonпјҢеҚҺдёәеӯҳеӮЁ huaweioceanstorпјҢжө·еә·hikvision IPsan пјҢеӨ§еҚҺ dahua IPsan
еӣҪеӨ–еӯҳеӮЁпјҡisilon
еҲҶеёғејҸеӯҳеӮЁпјҡSDS пјҡvsan,smarx, x-sky xsky иҪҜ件е®ҡд№үеӯҳеӮЁ еҲҶеёғеӯҳеӮЁ
дәҢзә§еӯҳеӮЁпјҡcdm 第дәҢеӯҳеӮЁ second storage
и¶…иһҚеҗҲhciпјҡnutanix ,ж·ұдҝЎжңҚ ,
NASдё“з”ЁзЎ¬зӣҳпјҡ
seagate еёҢжҚ· й…·зӢјironwolf пјҢй”ЎжҚ·seagateironwolf й…·зӢјpro пјҢWD westdigital зәўзӣҳ
й»‘зҫӨжҷ–ж— жі•еҚҮзә§пјҢжҳ“дёўеӨұж•°жҚ®пјҢе»әи®®з”ЁзҷҪзҫӨжҷ–пјҢй»‘зҫӨжҷ–жҙ—зҷҪ
дә§е“ҒпјҡеӣҪиЎҢеҺҹиЈ…жӯЈе“Ғ, SynologyзҫӨжҷ–科жҠҖе®ҳзҪ‘
synology partnerпјҡ
ж·ұеңіеёӮеҮҜжҙӣиңңиҙёжҳ“жңүйҷҗе…¬еҸё
ж·ұеңіеӣҪдәҝеӣҪйҷ…иҙёжҳ“жңүйҷҗе…¬еҸёпјҲж·ұеңіеӣҪдәҝеӣҪйҷ…)
дё–е№ідјҹдёҡеӣҪйҷ…иҙёжҳ“пјҲдёҠжө·пјүжңүйҷҗе…¬еҸёпјҲдёҠжө·дё–е№ідјҹдёҡ)
зҫӨжҷ–е®ҳзҪ‘пјҡsynology inc , зҫӨжҷ–科жҠҖе®ҳзҪ‘
жңҚеҠЎеҢәеҹҹпјҡеӣӣе·қзҫӨжҷ– жҲҗйғҪзҫӨжҷ– иҘҝи—ҸзҫӨжҷ– йҮҚеәҶзҫӨжҷ–иҙөе·һзҫӨжҷ– иҙөйҳізҫӨжҷ– дә‘еҚ—зҫӨжҷ– жҳҶжҳҺзҫӨжҷ–
еӣӣе·қsynology: еҫ·йҳізҫӨжҷ– з»өйҳізҫӨжҷ–пјҢж”ҖжһқиҠұзҫӨжҷ–пјҢиҘҝжҳҢзҫӨжҷ–пјҢйӣ…е®үзҫӨжҷ–пјҢеҶ…жұҹзҫӨжҷ–пјҢиө„йҳізҫӨжҷ–пјҢеҚ—е……зҫӨжҷ–пјҢзңүеұұзҫӨжҷ–пјҢд№җеұұзҫӨжҷ–пјҢиҮӘиҙЎзҫӨжҷ– жіёе·һзҫӨжҷ– е№ҝе…ғзҫӨжҷ– йҒӮе®ҒзҫӨжҷ– е®ңе®ҫзҫӨжҷ– е№ҝе®үзҫӨжҷ– иҫҫе·һзҫӨжҷ– йӣ…е®үзҫӨжҷ– е·ҙдёӯзҫӨжҷ– иө„йҳізҫӨжҷ– ж”ҖжһқиҠұзҫӨжҷ– еҮүеұұеҪқж—ҸиҮӘжІ»е·һзҫӨжҷ– з”ҳеӯңи—Ҹж—ҸиҮӘжІ»е·һзҫӨжҷ– йҳҝеққи—Ҹж—ҸзҫҢж—ҸиҮӘжІ»е·һзҫӨжҷ–
NASе“Ғзұ»пјҡ
еӯҳеӮЁжңҚеҠЎеҷЁпјҢNASзҪ‘з»ңеӯҳеӮЁжңҚеҠЎеҷЁпјҢзҫӨжҷ–NASзҪ‘з»ңеӯҳеӮЁпјҢsynology nas ,зҪ‘з»ңйҷ„еҠ еӯҳеӮЁ, nasеӯҳеӮЁеҷЁ, nasжңҚеҠЎеҷЁпјҢдјҒдёҡзә§зҪ‘з»ңеӯҳеӮЁеҷЁпјҢзҪ‘з»ңеӯҳеӮЁеҷЁпјҢNASдә‘еӯҳеӮЁпјҢзҪ‘з»ңеӯҳеӮЁжұ пјҢз§Ғжңүдә‘еӯҳеӮЁ
зҫӨжҷ–й…Қ件пјҡзҫӨжҷ–й’ҘеҢҷпјҢ зҫӨжҷ–зЎ¬зӣҳй’ҘеҢҷпјҢзҫӨжҷ–зЎ¬зӣҳжүҳжһ¶й’ҘеҢҷпјҢ
зҫӨжҷ–зҪ‘еҚЎпјҢ зҫӨжҷ–дёҮе…ҶзҪ‘еҚЎпјҢ зҫӨжҷ–еҶ…еӯҳпјҢ зҫӨжҷ–з”өжәҗпјҢ зҫӨжҷ–дё»жқҝ |
е”®еҗҺе®ўжңҚпјҡ
е…Қиҙ№жҸҗдҫӣд»ҘдёӢзҫӨжҷ–жҠҖжңҜж”ҜжҢҒжңҚеҠЎпјҡ
зҫӨжҷ–жҠҖжңҜж”ҜжҢҒ зҫӨжҷ–nasе”®еҗҺ зҫӨжҷ–е”®еҗҺ зҫӨжҷ–еӯҳеӮЁзӣҳ
зҫӨжҷ–е”®еҗҺжңҚеҠЎ зҫӨжҷ–nas зҫӨжҷ–nasе”®еҗҺ
е”®еҗҺ пјҡ
зі»еҲ—еҸ·жҹҘиҜўжҳҜеҗҰиҝҮдҝқпјҢзі»еҲ—еҸ·жҹҘиҜўжҳҜеҗҰеңЁдҝқ
зҫӨжҷ–ж•°жҚ®жҒўеӨҚпјҡ
жңҚеҠЎеҷЁж•°жҚ®жҒўеӨҚ raidж•°жҚ®жҒўеӨҚ nasж•°жҚ®жҒўеӨҚ еёҢжҚ·ж•°жҚ®жҒўеӨҚ иҘҝж•°зЎ¬зӣҳжҒўеӨҚ seagate ж•°жҚ®жҒўеӨҚ WDж•°жҚ®жҒўеӨҚ зҫӨжҷ–зЎ¬зӣҳж•°жҚ®жҒўеӨҚ зҫӨжҷ–ж•°жҚ®жҒўеӨҚ
д»ЈзҗҶдҪ“зі»пјҡ
synologyзҫӨжҷ–е…ЁеӣҪжҖ»д»ЈзҗҶгҖҒsynologyзҫӨжҷ–еӣҪд»ЈпјҢsynologyзҫӨжҷ–жҖ»д»ЈзҗҶпјҢsynologyзҫӨжҷ–жҖ»еҲҶй”Җе•ҶгҖҒsynologyзҫӨжҷ–жҺҲжқғз»Ҹй”Җе•ҶгҖҒsynologyзҫӨжҷ–е®ҳж–№д»ЈзҗҶе•Ҷпјү
ж–№жЎҲйҖӮз”ЁжңәеһӢпјҡ
2019еҮәе“Ғ-19зі»еҲ—пјҡ
ds1019+гҖҒ DS1219+ гҖҒUC300 RackStationгҖҒFS3400гҖҒFS3600гҖҒFS6400гҖҒHD6400гҖҒSA3200DгҖҒSA3400гҖҒSA3600гҖҒUC3200гҖҒDVA3219
18-зі»еҲ—:
FS1018гҖҒRS3618xsгҖҒDS3018xsгҖҒRS2818RP+гҖҒRS2418(RP)+гҖҒRS818(RP)+гҖҒDS918+гҖҒDS718+гҖҒDS418гҖҒDS418playгҖҒDS218+гҖҒDS218playгҖҒDS418jгҖҒDS218гҖҒDS218jгҖҒDS118гҖҒNVR1218пјӣ
17-зі»еҲ—:
FS3017гҖҒFS2017гҖҒRS18017xs+гҖҒRS4017xs+гҖҒRS3617xs+гҖҒRS3617RPxsгҖҒRS3617xsгҖҒRS217гҖҒDS3617xsгҖҒDS1817+гҖҒDS1517+гҖҒDS1817гҖҒDS1517гҖҒжү©еұ•жҹңпјҡ417sasгҖҒRX1217sasгҖҒRX1217гҖҒDX517пјӣ
16-зі»еҲ—пјҡ
RS18016xs+гҖҒRS2416RP+гҖҒRS2416+гҖҒDS916+гҖҒDS716+IIгҖҒDS716+гҖҒRS816гҖҒDS416гҖҒDS416playгҖҒDS416slimгҖҒDS416jгҖҒDS216+IIгҖҒDS216+гҖҒDS216playгҖҒDS216гҖҒDS216jгҖҒDS216seгҖҒDS116гҖҒNVR216гҖҒзҫӨжҷ–жү©еұ•жҹң RX1216sasпјӣ
15-зі»еҲ—:
RC18015xs+гҖҒDS3615xsгҖҒDS2015xsгҖҒRS815(RP)+гҖҒDS2415+гҖҒDS1515+гҖҒDS415+гҖҒRS815гҖҒDS1515гҖҒDS715гҖҒDS415playгҖҒDS215+гҖҒDS215jгҖҒDS115гҖҒDS115jгҖҒDS1815+пјӣ
14-зі»еҲ—:
RS3614xs+гҖҒRS2414(RP)+гҖҒRS814(RP)+гҖҒRS814гҖҒDS414гҖҒDS214+гҖҒDS214playгҖҒRS214гҖҒDS414jгҖҒDS414slimгҖҒDS214гҖҒDS214seгҖҒDS114гҖҒEDS14пјӣ
13-зі»еҲ—:
RS10613xs+гҖҒRS3413xs+гҖҒDS2413+гҖҒDS1813+гҖҒDS1513+гҖҒDS713+гҖҒDS413гҖҒDS213+гҖҒDS413jгҖҒDS413jгҖҒDS213гҖҒDS213jгҖҒDS213airпјӣ
12-зі»еҲ—:
DS112гҖҒDS112jгҖҒDS112+гҖҒDS212гҖҒDS212jгҖҒDS212+гҖҒDS412+гҖҒDS712+гҖҒDS1512+гҖҒDS1812+гҖҒDS3612xsгҖҒRS212гҖҒRS812гҖҒRS812+гҖҒRS812RP+гҖҒRS2212+гҖҒRS2212RP+гҖҒRS3412RPxsгҖҒRS412xsгҖҒRS412RPxsпјӣ
11-зі»еҲ—пјҡ
DS1511+гҖҒds2411+пјҢ RS3411xsгҖҒRS3411RPxsгҖҒDS3611xsпјҢжү©еұ•з®ұ DX1211гҖҒrx1211rp+, rs411
RS2211(RP)+пјҢRS3411(RP)xsпјҢRX1211(RP)пјӣ
10-зі»еҲ—пјҡDS1010+пјҢDS710+пјҢRS810(RP)+ ,rx410пјӣ
09-зі»еҲ—пјҡ
ds509+ пјҢrs409,rs409RP+,rx4пјӣ
ж—©жңҹзі»еҲ—пјҡds-101 пјӣ
зҫӨжҷ–й…Қ件пјҡ
M2D17 пјҢsynology зҫӨжҷ–зӣ‘жҺ§и®ёеҸҜиҜҒ
жҲҗйғҪ科жұҮ科жҠҖжңүйҷҗе…¬еҸё --- дё“дёҡж•°жҚ®еӨҮд»ҪжңҚеҠЎе•Ҷ
ж— и®әжӮЁзҡ„ITжһ¶жһ„жҳҜ жң¬ең°еҢ–гҖҒдә‘з«ҜгҖҒиҝҳжҳҜж··е’Ңдә‘ йғҪиғҪжҸҗдҫӣдёҖз«ҷејҸж•°жҚ®еӨҮд»Ҫж–№жЎҲгҖӮ
дә¬дёңзҫӨжҷ–synology еӨ©зҢ«зҫӨжҷ– зәҝдёӢд»ЈзҗҶжҠҖжңҜе’ЁиҜўжңҚеҠЎ
еӣӣе·қжҲҗйғҪзҫӨжҷ–е®ҳж–№жҺҲжқғж ёеҝғд»ЈзҗҶе•ҶпјҲдјҒдёҡзә§жңҚеҠЎе•Ҷпјү
еӣӣе·қжҲҗйғҪзҫӨжҷ–synologyи§ЈеҶіж–№жЎҲдёӯеҝғ
еӣӣе·қжҲҗйғҪзҫӨжҷ–synologyдҪ“йӘҢдёӯеҝғ
еӣӣе·қжҲҗйғҪsynologyзҫӨжҷ–зәҝдёӢе®һдҪ“еә—
еӣӣе·қжҲҗйғҪзҫӨжҷ–synologyе”®еҗҺжҠҖжңҜдёӯеҝғ
еӣӣе·қжҲҗйғҪзҫӨжҷ–synologyе®ҳж–№жҺҲжқғдё“еҚ–еә—

жҲҗйғҪ科жұҮ科жҠҖжңүйҷҗе…¬еҸё
ең°еқҖпјҡжҲҗйғҪеёӮдәәж°‘еҚ—и·Ҝеӣӣж®ө1еҸ·ж—¶д»Јж•°з ҒеӨ§еҺҰ18F
з”өиҜқпјҡ400-028-1235
QQ: 2231749852
жүӢжңәпјҡ138 8074 7621пјҲеҫ®дҝЎеҗҢеҸ·