




ж–°й—»иҜҰжғ…
ж–°й—»жҗңзҙў
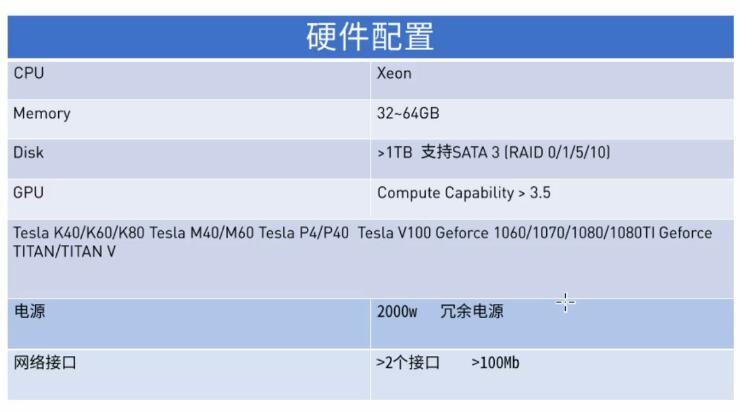
nividia GPU й…ҚзҪ®гҖӮ
жёёжҲҸеҚЎпјҢдёҚиғҪдҪңдёәGPUиҝҗз®—зҡ„гҖӮ
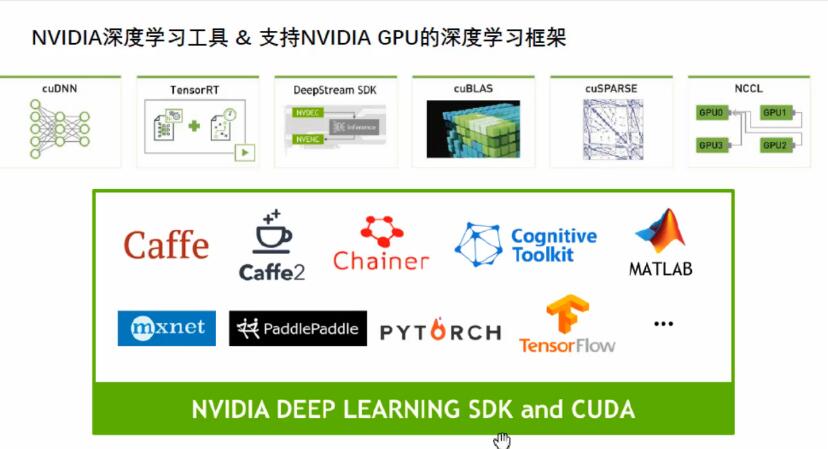




ж·ұеәҰеӯҰд№ жңҚеҠЎеҷЁпјҢжҳҜиҝ‘еҮ е№ҙйғҪжҜ”иҫғзҒ«зҡ„пјҢе°Ө其科еӯҰйҷўжүҖпјҢејҖеҸ‘пјҢйғЁзҪІпјҢйғҪйңҖиҰҒ ж·ұеәҰеӯҰд№ жңҚеҠЎеҷЁгҖӮ
70-80%пјҢз”ЁдәҺ
пјҢ1-ж·ұеәҰеӯҰд№ зҡ„жЁЎеһӢи®ӯз»ғгҖӮ
2-и®ӯз»ғж ·жң¬зҡ„з®ЎзҗҶпјҢпјҲеӣҫзүҮпјҢиҜӯеҚ•пјҢиҜӯж–ҷпјҢзҙ жқҗз®ЎзҗҶеҸҠ --йңҖиҰҒеӨ§еҶ…еӯҳгҖӮпјҲ32-64GBпјүд»ҘдёҠгҖӮ
еӨҡGPUеҚЎпјҢиө·з ҒпјҢеҶ…еӯҳиҰҒжҜ”жҳҫеӯҳиҰҒеӨ§е“ҲгҖӮжүҚиғҪзј“еҶІдёӢиҝҷдәӣж•°жҚ®гҖӮ
зЎ¬зӣҳиҰҒдҝқз®ЎпјҢж ·жң¬йӣҶпјҢзӯүгҖӮиҝҳиҰҒеҒҡraid ,иҰҒ1Tд»ҘдёҠгҖӮ
3--и®ӯз»ғжЁЎеһӢйғЁзҪІгҖӮпјҲ30-40% еңәжҷҜпјү
жҸҗдҫӣдәҶдёҚеҗҢзҡ„е·Ҙе…·гҖӮ
telsa жңҚеҠЎеҷЁз«Ҝ
geforce жёёжҲҸз«Ҝ
qudro еӣҫеҪўе·ҘдҪңз«ҷ
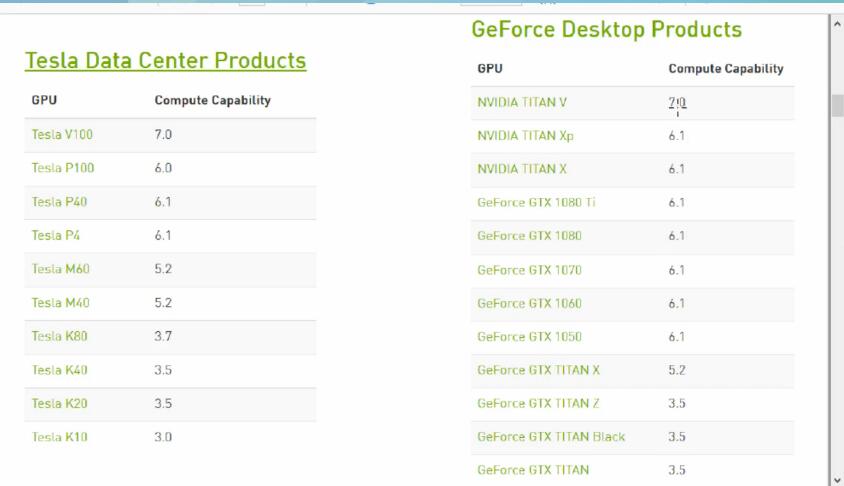
жңҖж–°е·Ҙе…·иҰҒGPUз®—еҠӣпјҢеӨ§дәҺ3.5
ж–°жүӢпјҢеҸҜд»ҘйҖүжӢ©пјҢgeforce жқҘеҒҡз®ҖеҚ•зҡ„ж·ұеәҰеӯҰд№ гҖӮ
еӨҡеҚЎпјҢж №жҚ®еҠҹзҺҮжҖ»е’ҢгҖӮиҰҒ2000Wд»ҘдёҠгҖӮеҚ•еҚЎзҡ„иҜқпјҢдҪҺзӮ№д№ҹжІЎдәӢгҖӮ
еҶ—дҪҷз”өжәҗпјҢзЎ®дҝқдёҡеҠЎдёҚдёӯж–ӯгҖӮ
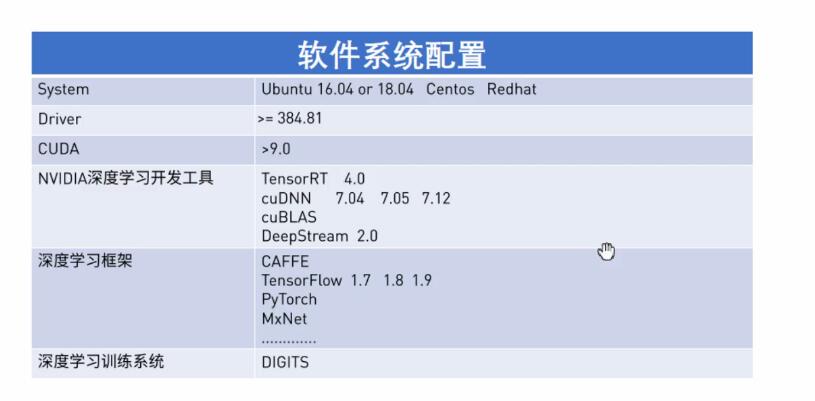
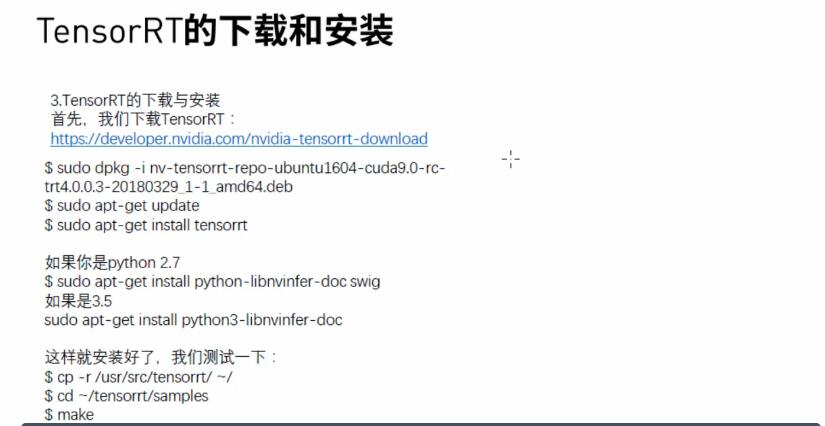
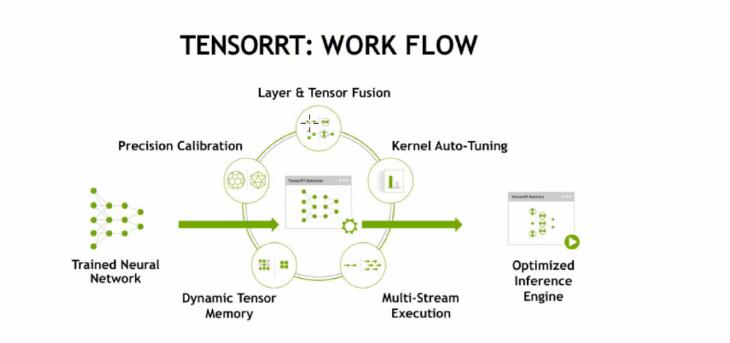
tensor RT :й’ҲеҜ№ жҺЁзҗҶпјҢиҝӣиЎҢдјҳеҢ–пјҢеҠ йҖҹ пјҢеҢ…жӢ¬зҪ‘з»ңжЁЎеһӢиЈҒеүӘгҖӮеҶ…ж ёи°ғз”ЁгҖӮеҸӘйңҖи°ғз”ЁдёҖдёӘengienеҚіеҸҜгҖӮ
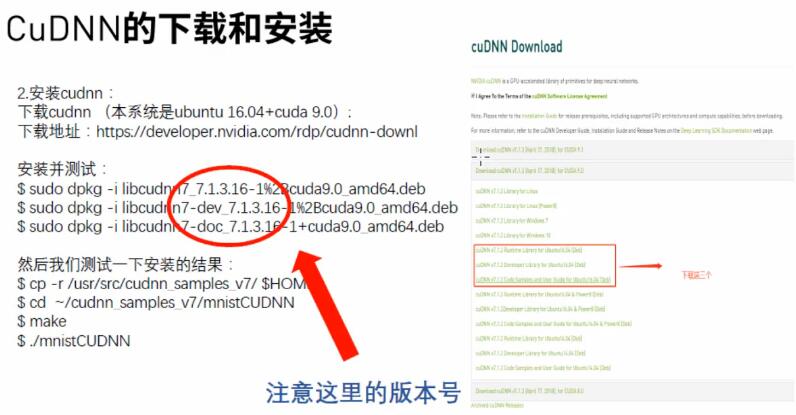
cudnn,дёҖдёӘйӣҶжҲҗеә“пјҢжҺҘиҝ‘дәҺи®ӯз»ғзҡ„еҶ…е®№гҖӮ
cublas.жӣҙдҪҺеұӮпјҢе®үиЈ…cudaa,е°ұе·Іе®үиЈ…еҘҪдәҶгҖӮ
deepstream 2.0 дёҖж•ҙеҘ—ж–№жЎҲпјҢе…ідәҺи§Ҷйў‘пјҢдёҚз”Ёе…іжіЁз»ҶиҠӮгҖӮе®ғжҳҜдёҖдёӘжЎҶжһ¶гҖӮйғЁзҪІдёҖж¬Ўе°ұOKпјҢйӣҶжҲҗеҘҪдәҶеҫҲеӨҡе·Ҙе…·пјҢз•ҷз»ҷдҪ зҡ„е°ұжҳҜжғіеғҸиғҪеҠӣгҖӮ
жЎҶжһ¶пјҢж— и®әжҳҜtraining з«ҜпјҢиҝҳжҳҜinfluendз«ҜпјҢ
nvidia ејҖжәҗзҡ„пјҢе°ұжҳҜdigits . жүҖжңүејҖжәҗжЎҶжһ¶пјҢйғҪйҖӮеә”дәҺGPUпјҢеҫҲеӨҡжҳҜе…Қиҙ№з”Ёзҡ„гҖӮ
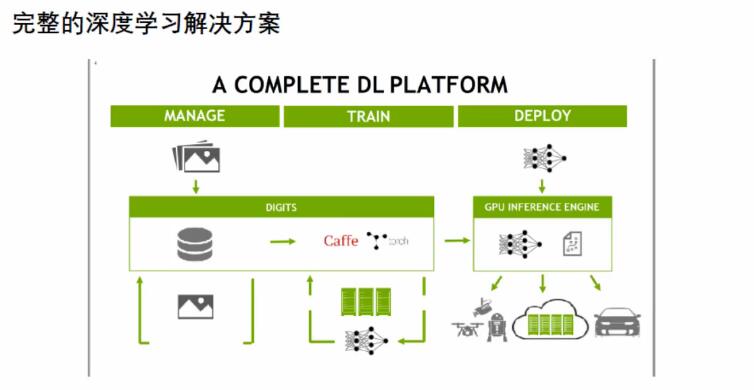
digits,жҳҜдёҖдёӘdashbold ,дёҖдёӘз®ЎзҗҶеҘ—件гҖӮз®ЎзҗҶ组件гҖӮйҖҡиҝҮжҸ’件пјҢж”ҜжҢҒдёҖдәӣжү©еұ•
и®ӯз»ғпјҢж—¶пјҢе®һж—¶жҖ§пјҢйҖҹеәҰдёҚиҰҒжұӮеҝ«гҖӮ дҪҶжҲ‘们йғЁзҪІж—¶пјҢжҺЁзҗҶж—¶пјҢиҰҒеҝ«гҖӮ
digits з®ЎзҗҶе·Ҙе…·гҖӮ
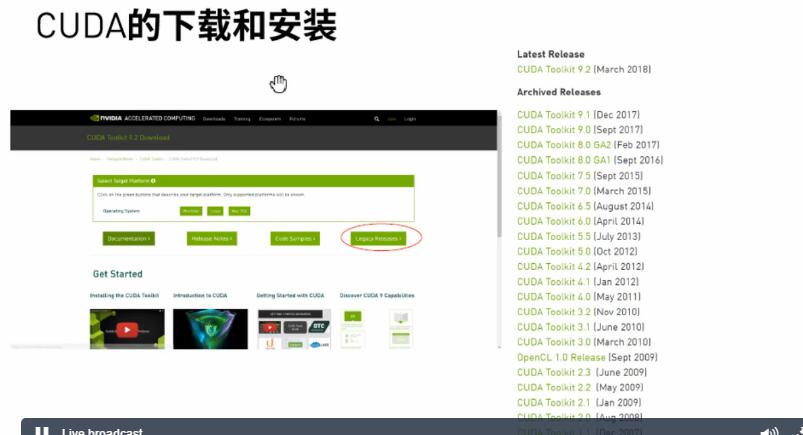
cudaзҡ„е®үиЈ…
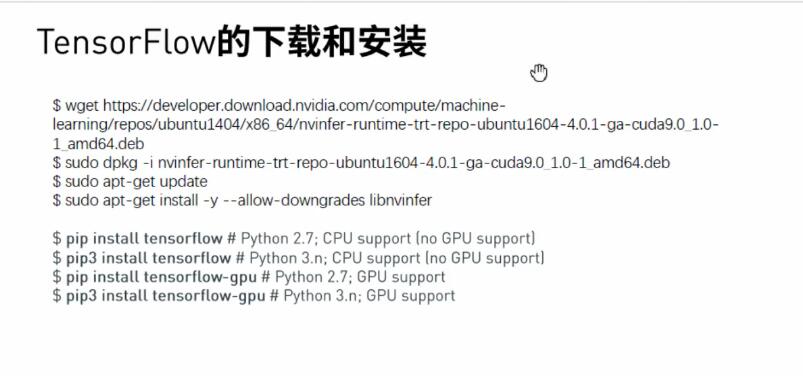
з”Ёdebж–№ејҸе®үиЈ…пјҢзӣёеҪ“дәҺзјәзңҒжЁЎејҸжЁЎејҸе®үиЈ…пјҢз®ҖеҚ•гҖӮ
20-30%пјҢй—®йўҳпјҢе…ідәҺзҺҜеўғеҸҳйҮҸпјҢжІЎжңүеҠ иҪҪеҜ№гҖӮ
CUdnn,жҳҜдёҖдёӘеҠ йҖҹе·Ҙе…·пјҢеҸҜд»ҘзңҒдёҖеҚҠзҡ„ж—¶й—ҙпјҢеҫҲеҝ«гҖӮ
ж–°жүӢгҖӮdbnзҡ„ж–Ү件дёҠпјҢжіЁж„ҸзүҲ жң¬еҸ·зҡ„еҢ№й…ҚгҖӮlib,dll.docж–Ү件иҰҒй…ҚгҖӮ
и®°еҫ—е®үиЈ…еә“пјҢеҗҰеҲҷpaphonдјҡзјәдёңиҘҝгҖӮ sample жңүдёҖдәӣе®һдҫӢпјҢжЎҲдҫӢгҖӮжҜ”иҫғе…ЁгҖӮдёҚз”ЁиҜ»ж•ҷжқҗ пјҢзӣҙжҺҘи®ҜејҖеҸ‘иҖ…жҢҮеҚ—пјҢеҢ…еҗ«дәҶжүҖжңүз»ҶиҠӮгҖӮ
tesorflow ,еҢ…еҗ«дәҶtensort. жүҖжңүеҠҹиғҪдәҶе“ҲгҖӮ
coffe, tesonflow ,tensorRT жҳҜдёҖдёӘlevelзҡ„дёңиҘҝгҖӮ

